

 État de la Science des Données 2024 : 6 tendances clés
État de la Science des Données 2024 : 6 tendances clésselon la dernière enquête de JetBrains et la Python Software Foundation
LIA générative et les grands modèles de langage (LLM) ont fait la une des sujets de discussion en 2024, mais ont-ils eu un véritable impact sur les tendances en matière de science des données et de machine learning ? Quelles sont les nouvelles tendances de la science des données qui valent la peine dêtre suivies ? Tous les ans, JetBrains et la Python Software Foundation mènent une enquête auprès des développeurs Python afin de collecter des informations qui aident à répondre à ces questions.
Les résultats de la dernière édition de cette enquête, issus de réponses obtenues entre novembre 2023 et février 2024, incluaient une nouvelle section dédiée à la science des données, ce qui a permis dobtenir une meilleure vue densemble des tendances dans ce domaine, et notamment de constater que le taux dutilisation de Python restait globalement élevé.
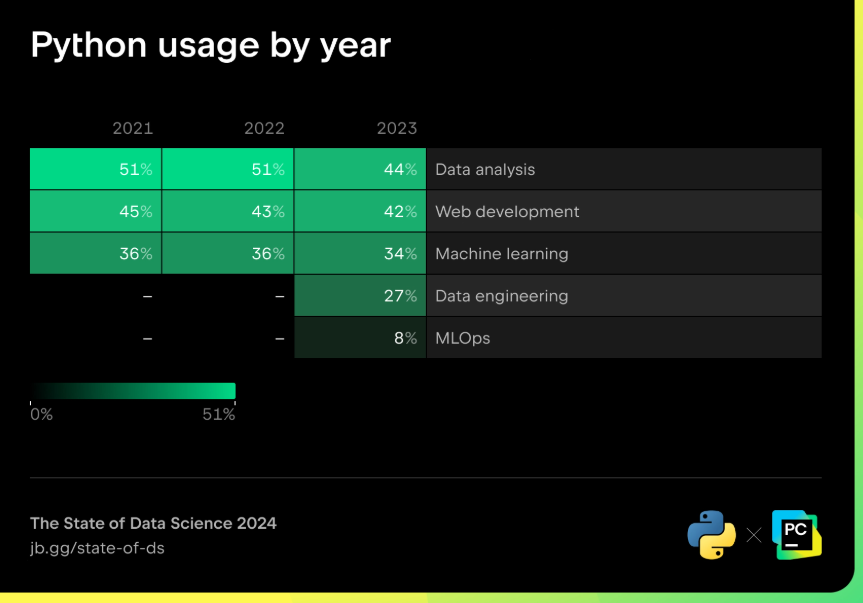
Utilisation de Python par année
Alors que 48 % des développeurs Python travaillent sur lexploration et le traitement des données, le pourcentage des répondants lutilisant pour lanalyse de données a baissé, passant de 51 % en 2022 à 44 % en 2023. Lutilisation de Python pour le machine learning est quant à elle passée de 36 % en 2022 à 34 % en 2023. Dans le même temps, 27 % des répondants ont déclaré utiliser Python pour lingénierie des données, tandis que 8 % lutilisent pour le MLOps, deux catégories qui ont fait leur apparition dans lédition 2023 de lenquête.
Nous examinons ici plus en détail les tendances révélées par lenquête afin de les contextualiser et de mieux les interpréter. Ce qui vous permettra d'en savoir plus sur les derniers développements dans les domaines de la science des données et du machine learning et bien vous préparer à 2025.
Traitement des données : pandas reste le premier choix, mais Polars gagne du terrain
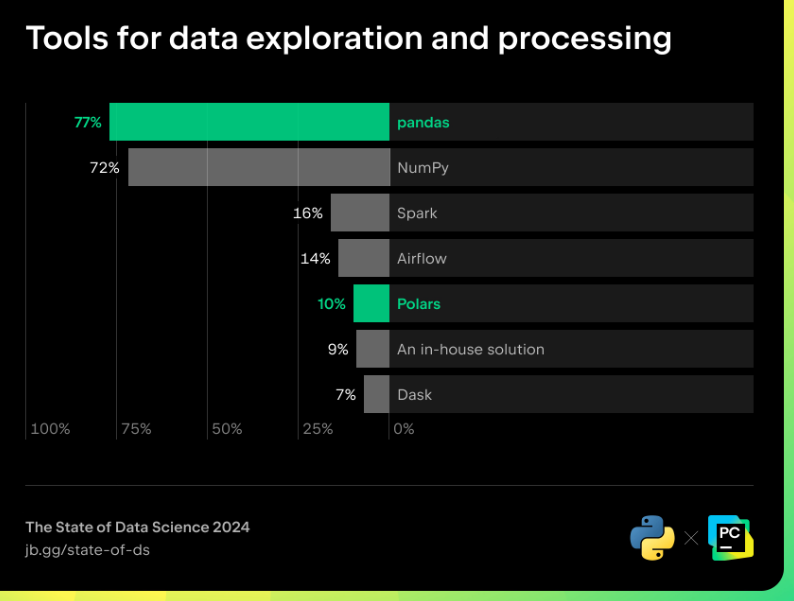
Le traitement des données est un aspect essentiel de la science des données. pandas est un projet qui a déjà 15 ans, mais il demeure loutil de traitement des données le plus prisé : 77 % des répondants qui travaillent sur lexploration et le traitement des données déclarent lutiliser. En tant que projet mature, son API est stable et de nombreux exemples de code peuvent être trouvés sur Internet, il nest donc pas surprenant quil soit le premier choix. Sponsorisé par NumFOCUS, le projet pandas a démontré quil était durable et son modèle de gouvernance a gagné la confiance des utilisateurs. Cest un excellent choix pour les débutants qui ne maîtrisent pas encore le traitement des données, car il sagit dun projet stable qui nest pas sujet à des changements rapides.
De son côté, Polars, qui se présente comme le DataFrames du futur, a été au centre de lattention ces deux dernières années grâce à ses atouts en termes de vitesse et de traitement parallèle. En 2023, une entreprise dirigée par le créateur de Polars, Ritchie Vink, a été créée afin daccompagner la progression de ce projet et de permettre à Polars de conserver un rythme de développement rapide. La version 1.0 de Polars a été publiée en juillet 2024. Par la suite, Polars a étendu sa compatibilité avec dautres outils de science des données populaires, comme Hugging Face et NVIDIA RAPIDS. Il fournit également un backend léger pour générer des graphiques, tout comme pandas.
Il peut donc être intéressant pour les professionnels de la science des données de passer à Polars. En gagnant en maturité, il pourrait devenir un outil essentiel dans le workflow de science des données et être utilisé pour traiter davantage de données plus rapidement. Dans lenquête de 2023, seulement 10 % des répondants disaient utiliser Polars comme outil de traitement des données, mais il est probable que le nombre de ses utilisateurs augmente à lavenir.
Outils d'exploration et de traitement des données
Que vous soyez un professionnel confirmé ou que vous commenciez à travailler sur vos premiers jeux de données, il est important de disposer dun outil efficace, qui rende votre travail à la fois plus productif et agréable. Rappelons qu'avec PyCharm, vous pouvez inspecter vos données sous forme de tables interactives, que vous pouvez faire défiler, trier, filtrer, convertir en graphiques ou utiliser pour générer des cartes thermiques. De plus, il vous permet dobtenir des résultats danalyse pour chaque colonne et de bénéficier de lassistance par IA pour expliquer les DataFrames ou créer des visualisations. Cette fonctionnalité de PyCharm est disponible non seulement pour les dataframes pandas et Polars, mais aussi pour les jeux de données Hugging Face, NumPy, PyTorch et TensorFlow.
Une table interactive dans PyCharm Pro fournit des outils permettant dinspecter les DataFrames pandas et Polars
La popularité de Polars a mené à la création dun nouveau projet appelé Narwhals. Indépendant de pandas et Polars, Narwhals vise à unifier les API de ces deux outils (et de nombreux autres). Comme il sagit dun projet assez récent (débuté en février 2024), il napparaît pas encore sur la liste des outils de traitement des données les plus populaires, mais JetBrains pense quil devrait y figurer dans quelques années.
Un taux de 16 % des répondants disent utiliser Spark, contre 7% pour Dask. Ces deux outils ont en commun de permettre de traiter de gros volumes de données grâce à leurs processus de traitement parallèle. Leur mise en place requiert des capacités dingénierie un peu plus avancées, mais dans la mesure où la quantité de données dont dépendent les projets dépasse de plus en plus ce quun programme Python traditionnel peut gérer, leur taux dutilisation sera certainement amené à augmenter.
Visualisation des données : HoloViz Panel va-t-il bientôt supplanter Plotly Dash et Streamlit ?
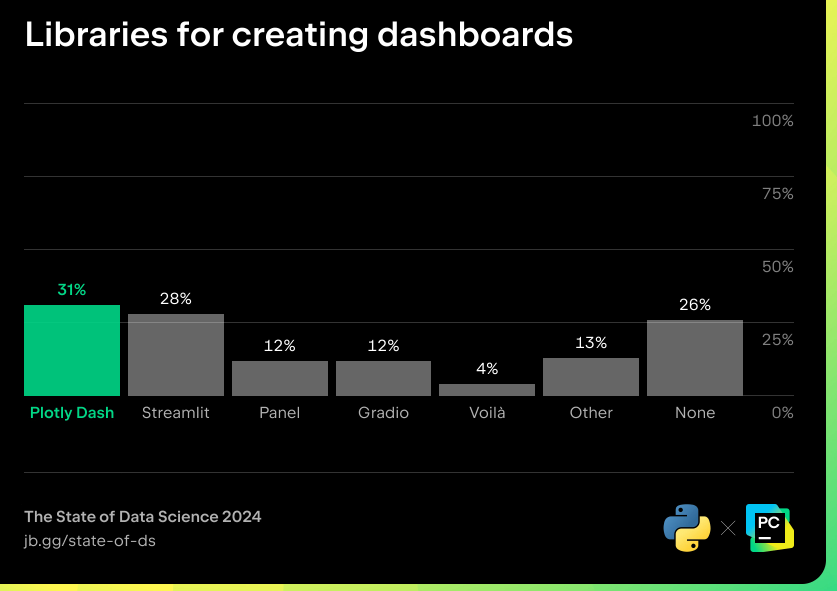
Lun des principaux rôles des data scientists est de créer des rapports et dexpliquer leurs découvertes et conclusions au regard des enjeux et des problématiques stratégiques de lentreprise. Plusieurs outils de visualisation de tableaux de bord interactifs ont été développés pour travailler avec Python. Daprès les résultats de l'enquête de JetBrains et la Python Software Foundation, le plus populaire dentre eux est Plotly Dash.
Bibliothèques pour créer des tableaux de bord
Au sein de la communauté de la science des données, Plotly était initialement connu surtout pour ggplot2, une bibliothèque de visualisation très populaire parmi les utilisateurs du langage R. Mais Plotly a pris en compte la croissance de lutilisation de Python pour la science des données et fournit aussi une bibliothèque Python, qui offre une expérience similaire à celle de ggplot2 en Python. Ces dernières années, opter pour Dash, le framework Python développé par Plotly pour créer des applications web réactives, est devenu une évidence pour les utilisateurs de Plotly ayant besoin de créer un tableau de bord interactif. Cependant, lAPI de Dash requiert une connaissance de base des éléments utilisés dans le code HTML pour la conception de la mise en page dune application. Pour les personnes ayant peu ou pas dexpérience du frontend, cela peut constituer un obstacle à une utilisation efficace de Dash.
Streamlit, qui est maintenant associé à Snowflake, arrive second dans la catégorie des outils de création de tableaux de bord. Cet outil est plus récent que Plotly, mais il monte en puissance depuis quelques années, car il est facile à utiliser et inclut un outil de ligne de commande. Bien que Streamlit ne soit pas aussi personnalisable que Plotly, ses présentations de tableaux de bord sont assez faciles à créer et il prend en charge les applications multipages, ce qui permet de concevoir des applications plus complexes.
Mais de nouveaux outils émergents pourraient bientôt égaler, voire surpasser, ces applications en termes de popularité. Lun dentre eux est HoloViz Panel, lune des bibliothèques de lécosystème HoloViz, qui est sponsorisée par NumFocus et gagne du terrain au sein de la communauté PyData. Panel permet de générer des rapports au format HTML et fonctionne également très bien avec les notebooks Jupyter. Elle fournit des modèles pour aider les nouveaux utilisateurs à bien démarrer, ainsi que de nombreuses options de personnalisation pour les utilisateurs expérimentés qui souhaitent affiner leurs tableaux de bord.
Modèles de ML : la prédominance de scikit-learn se confirme, tandis que PyTorch est le plus populaire pour le deep learning
LIA générative et les LLM ayant beaucoup fait parler deux au cours des dernières années, on pourrait sattendre à ce que les frameworks et les bibliothèques de deep learning aient complètement pris le dessus, mais cela nest pas tout à fait le cas. Il reste encore beaucoup dinformations qui peuvent être extraites des données au moyen des méthodes statistiques traditionnelles offertes par scikit-learn, une bibliothèque de machine learning reconnue et principalement gérée par des chercheurs. Sponsorisée par NumFocus depuis 2020, elle demeure la bibliothèque la plus importante pour le machine learning et la science des données. SciPy, une autre bibliothèque Python offrant la prise en charge des calculs scientifiques, figure aussi parmi des bibliothèques les plus utilisées pour la science des données.
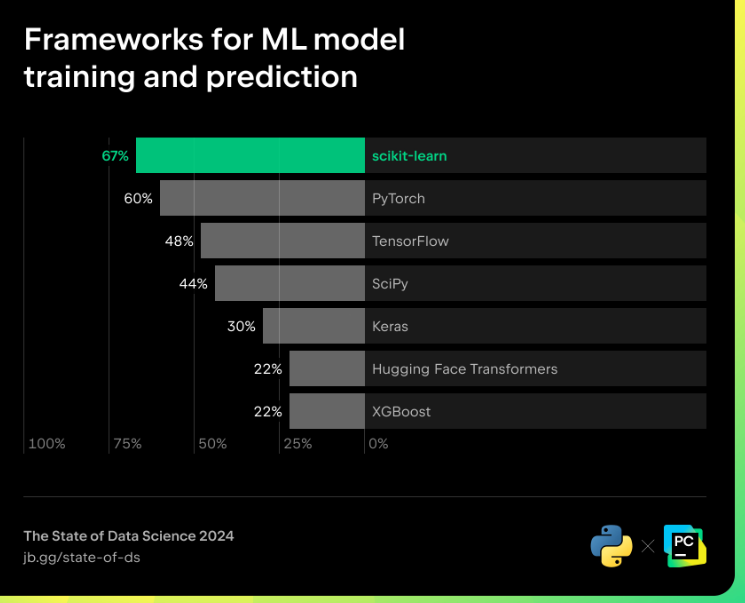
Frameworks pour l'entraînement des modèles de ML et la prédiction
Pour autant, on ne peut pas ignorer limpact du deep learning et laugmentation de lutilisation des frameworks de deep learning. PyTorch, une bibliothèque de machine learning créée par Meta, est désormais sous la gouvernance de la Linux Foundation. Sur la base de ce changement, on peut sattendre à ce que PyTorch reste une bibliothèque majeure de lécosystème open source et que sa communauté maintiendra un niveau actif dimplication. Cest le framework de deep learning le plus utilisé et il est particulièrement apprécié par les utilisateurs de Python, notamment par ceux qui sont familiers avec NumPy, car les « tenseurs », qui sont les structures de données de base de PyTorch, sont très similaires aux tableaux NumPy.
Vous pouvez inspecter les tenseurs PyTorch dans PyCharm Pro tout comme vous le faites pour les tableaux NumPy
Contrairement à TensorFlow, qui utilise un graphe de calcul statique, PyTorch utilise un graphe dynamique, ce qui facilite grandement le profilage en Python. De plus, PyTorch fournit une API de profilage, ce qui en fait un excellent choix pour la recherche et lexpérimentation. Toutefois, si votre projet de deep learning requiert un déploiement évolutif et doit prendre en charge plusieurs langages de programmation, il peut être préférable dopter pour TensorFlow, qui est compatible avec de nombreux langages, parmi lesquels C++, JavaScript, Python, C#, Ruby et Swift. Keras est un outil qui rend TensorFlow plus accessible, et qui est aussi populaire pour les frameworks de deep learning.
Hugging Face Transformers est un autre framework incontournable pour le deep learning. Hugging Face est un hub qui fournit de nombreux modèles de deep learning très avancés et pré-entraînés, qui sont très appréciés par les communautés de la science des données et du machine learning, et que vous pouvez télécharger et entraîner davantage vous-même. Transformers est une bibliothèque maintenue par Hugging Face et sa communauté, pour un machine learning de pointe avec PyTorch, TensorFlow et JAX. Avec la popularité des LLM, Hugging Face Transformers devrait prochainement attirer encore plus dutilisateurs.
Rappelons que PyCharm permet didentifier et de gérer les modèles Hugging Face dans une fenêtre doutils dédiée. Il vous aide également à choisir le bon modèle pour votre cas dutilisation à partir dun grand nombre de modèles Hugging Face, directement dans lEDI.
Scikit-LLM est une bibliothèque récente dont le principal intérêt est de permettre dexploiter des modèles dOpen AI comme ChatGPT et de les intégrer avec scikit-learn. Vous pouvez notamment effectuer une analyse de texte à laide des modèles de scikit-learn et bénéficier de la puissance de modèles de LLM modernes.
MLOps : le futur des projets de science des données
Le MLOps (opérations de machine learning) constitue un aspect essentiel mais souvent négligé des projets de science des données. Dans le workflow des projets de science des données, les data scientists doivent gérer les données, re-entraîner le modèle et contrôler les versions pour toutes les données et les modèles utilisés. Parfois, lorsquune application de machine learning est déployée en production, il est aussi nécessaire dobserver et de surveiller ses performances et son utilisation.
Des outils de MLOps conçus pour les projets de science des données ont fait leur apparition au cours des dernières années. Lun des principaux problèmes pour les data scientists et les ingénieurs de données est le versioning des données, un élément crucial lorsque votre pipeline reçoit constamment des données.
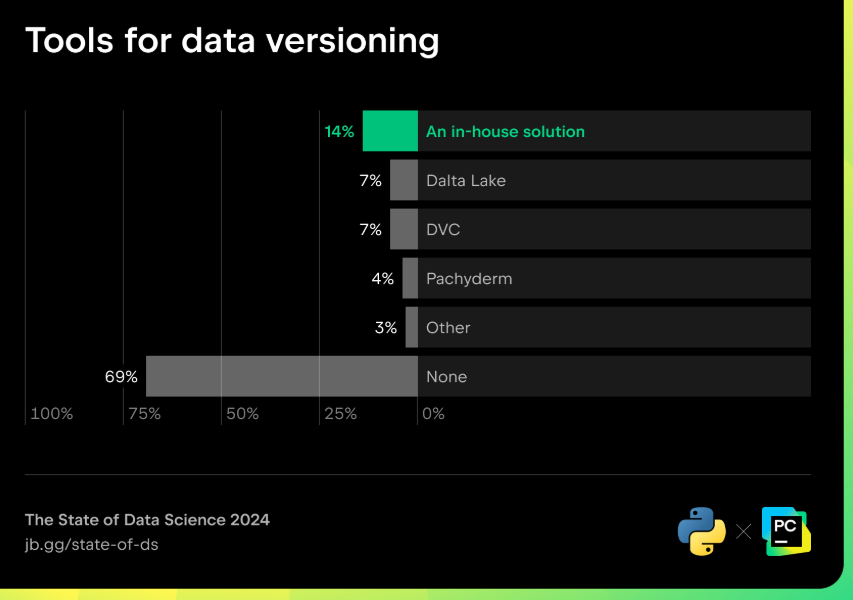
Outils pour le versioning des données
Les data scientists et les ingénieurs des données doivent également pouvoir suivre leurs expérimentations. Étant donné que le modèle de machine learning sera ré-entraîné avec de nouvelles données et que les hyperparamètres seront affinés, il est important de pouvoir garder une trace du modèle dentraînement et des résultats des expérimentations.
Actuellement, loutil le plus populaire pour cela est TensorBoard. Toutefois, cela pourrait changer bientôt. TensorBoard.dev ayant été déprécié, les utilisateurs doivent donc maintenant déployer leurs propres installations TensorBoard localement ou partager les résultats en utilisant lintégration de TensorBoard avec Google Colab. Par conséquent, lutilisation de TensorBoard risque de diminuer au profit dautres outils tels que MLflow et PyTorch.
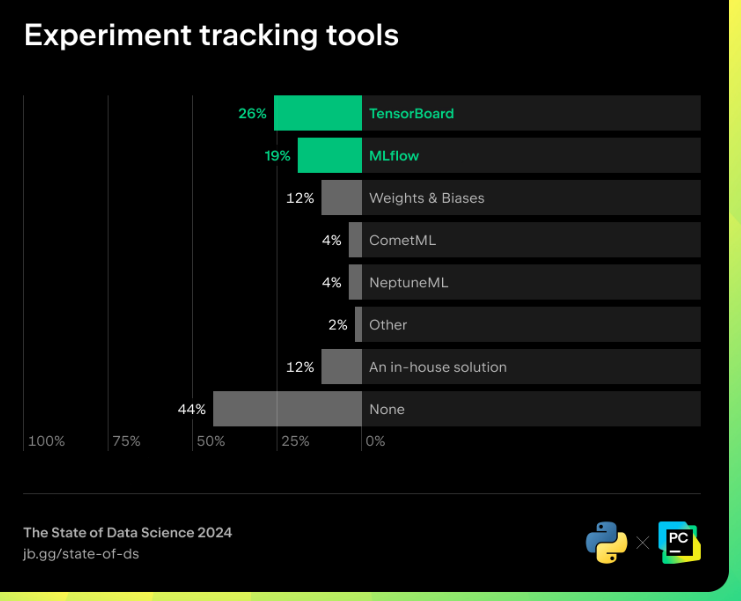
Outils de suivi des expérimentations
La mise en production de lenvironnement de développement est une autre étape de MLOps nécessaire au bon déroulement des projets de données. Lutilisation de conteneurs Docker, une pratique courante de développement chez les ingénieurs logiciels, semble avoir également été adoptée par la communauté des data scientists. Elle permet dassurer que les environnements de développement et de production restent cohérents, ce qui est important pour les projets de science des données impliquant des modèles de machine learning qui doivent être déployés en tant quapplications. Nous pouvons voir que Docker est plébiscité par les utilisateurs de Python qui ont besoin de déployer des services sur le cloud.
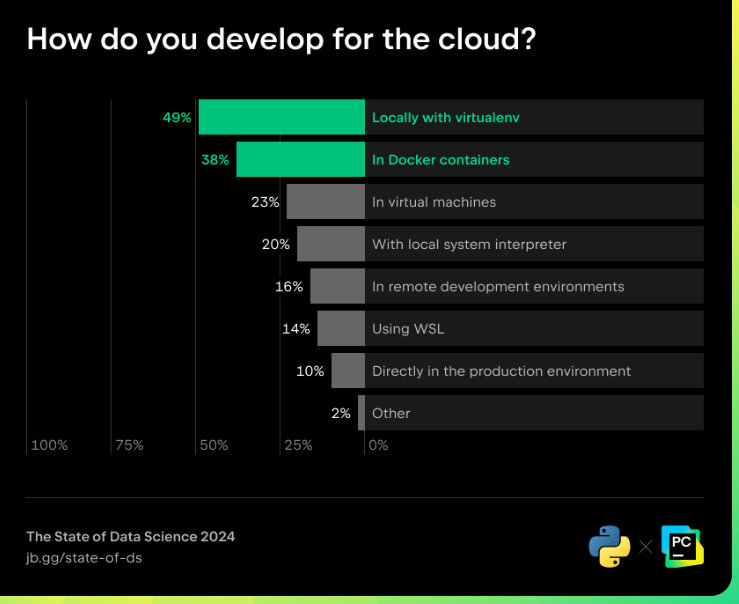
Comment développez-vous pour le cloud ?
Les conteneurs Docker devancent légèrement Anaconda dans la catégorie « Installation et mise à niveau de Python ».
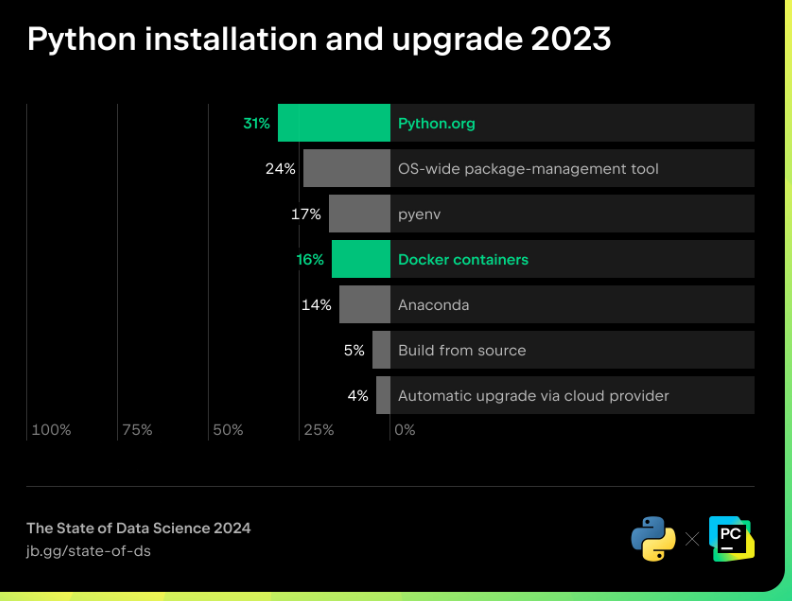
Installation et mise à niveau de Python - Résultats de lenquête 2023
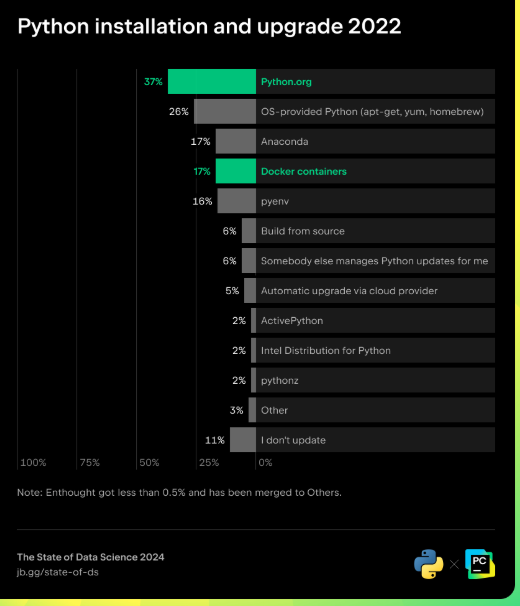
Installation et mise à niveau de Python - Résultats de lenquête 2022
Big data : quelle quantité de données est suffisante ?
Lune des principales idées reçues concernant le big data est que nous aurons besoin de plus de données pour entraîner des modèles plus performants et complexes afin daméliorer les prédictions. Pourtant, cela nest pas le cas. Les modèles pouvant être surajustés, plus ne veut pas forcément dire mieux en matière de machine learning. Différents outils et approches peuvent être requis en fonction du cas dutilisation, du modèle et de la quantité de données traitées simultanément.
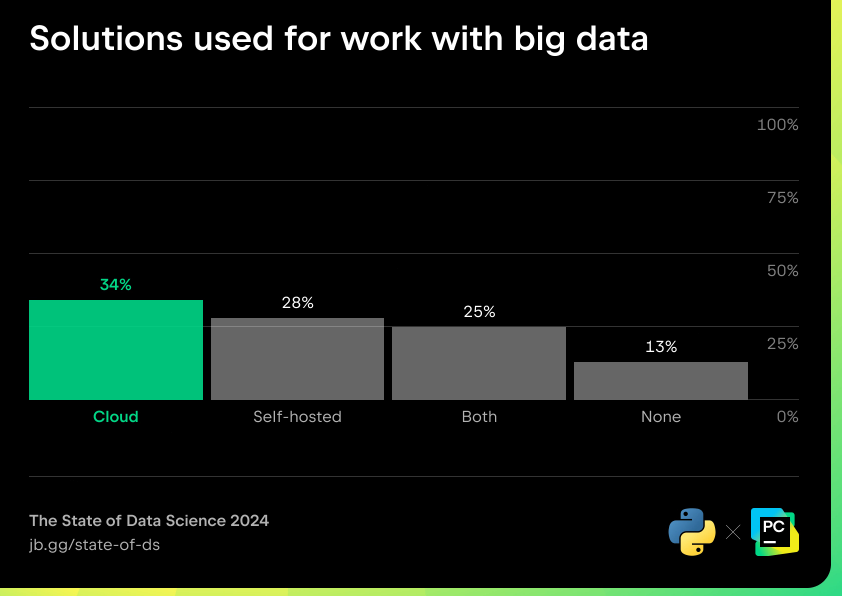
Solutions de big data
Le défi lié à la gestion de grandes quantités de données en Python provient du fait que la plupart des bibliothèques Python reposent sur le stockage des données en mémoire. On pourrait déployer des ressources de cloud computing avec de grandes quantités de mémoire, mais même cette approche a ses limites et peut parfois se révéler lente et coûteuse.
Pour traiter de grandes quantités de données difficiles à stocker en mémoire, une solution commune consiste à utiliser des ressources informatiques distribuées. Les tâches et les données sont réparties dans un cluster pour être exécutées et traitées en parallèle. Cette approche rend les opérations de science des données et de machine learning évolutives, et le moteur le plus utilisé pour cela est Apache Spark. Spark peut être utilisé avec la bibliothèque dAPI Python PySpark.
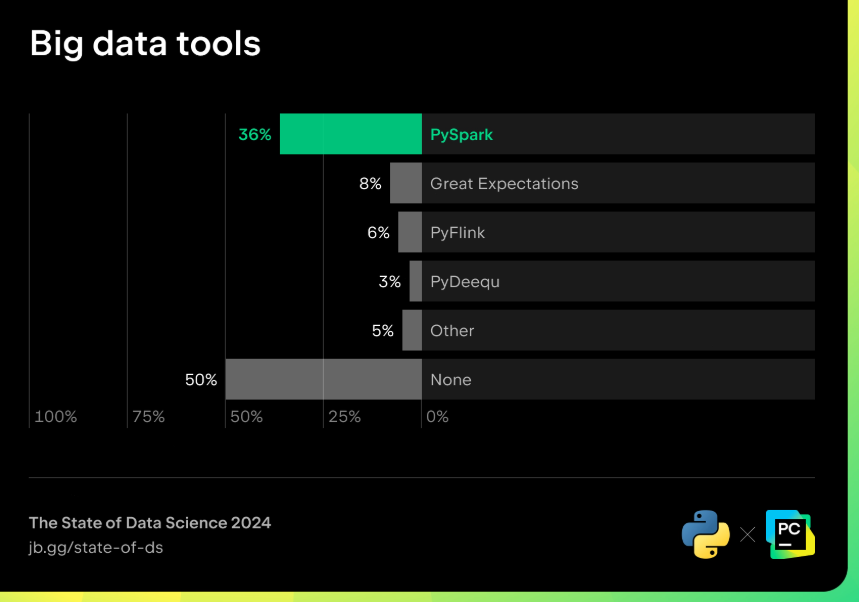
Outils big data
Concernant Spark 2.0, il est recommandé aux utilisateurs de lAPI RDD de Spark de passer à Spark SQL, qui offre de meilleures performances. Spark SQL facilite également le traitement des données pour les data scientists, car il permet dexécuter des requêtes SQL. PySpark devrait rester le choix le plus populaire en 2024.
Databricks est un autre outil populaire pour la gestion des données dans les clusters. Si vous utilisez Databricks pour travailler sur vos données dans des clusters, vous profiter de lintégration puissante de Databricks et PyCharm qui permet décrire du code pour vos pipelines et vos tâches dans PyCharm, puis de le déployer, de le tester et de lexécuter en temps réel sur votre cluster Databricks sans configuration supplémentaire.
Communautés : les événements mettent de plus en plus en avant la science des données
La plupart des personnes qui commencent à utiliser Python le font pour des activités de science des données et de plus en plus de bibliothèques Python sont donc consacrées aux cas dutilisation dans ce domaine. Par ailleurs, les événements Python comme PyCon et EuroPython commencent à proposer davantage de présentations, déchanges et dateliers dédiés à la science des données, et les événements portant spécifiquement sur ce domaine tels que PyData et SciPy sont toujours autant appréciés.
Pour conclure
De plus en plus de nouveaux outils open source sont disponibles en réponse au dynamisme croissant de la science des données et du machine learning et à la popularité de lIA et des LLM. Lunivers de la science des données continue à évoluer rapidement, alors on peut s'attendre à voir des changements dans la prochaine enquête.
Science des données avec PyCharm
La science des données moderne requiert des compétences pour une large gamme de tâches, parmi lesquelles le traitement des données et la visualisation, le code, le déploiement de modèles et la gestion de grands jeux de données. En tant quenvironnement de développement intégré (EDI), PyCharm vous aide à développer ces compétences. Il fournit une assistance intelligente au codage, un débogage de haut niveau, le contrôle de version, la gestion intégrée des bases de données et une intégration fluide avec Docker. Pour la science des données, PyCharm prend en charge les notebooks Jupyter, ainsi que les bibliothèques scientifiques et de machine learning clés, et il sintègre avec des outils tels que la bibliothèque de modèles Hugging Face, Anaconda et Databricks.
JetBrains vous donc à tester PyCharm pour vos projets de science des données et profiter de ses dernières améliorations, telles que linspection des DataFrames pandas et Polars, linspection des tenseurs PyTorch couche par couche pour lexploration des données et la création de modèles de deep learning.
 Essayez PyCharm gratuitement
Essayez PyCharm gratuitement
Vous avez lu gratuitement 654 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.

