

 DataSpell 2024.1 disponible
DataSpell 2024.1 disponibleL'EDI pour la science des données apporte une meilleure prise en charge de dbt, la possibilité d'interroger des trames de données via des cellules SQL, et bien plus
DataSpell 2024.1 est disponible. Il s'agit de la première mise à jour de l'année de l'EDI de JetBrains pour la science des données. Cette version vient avec un bon lot de nouveautés et améliorations dans divers domaines.
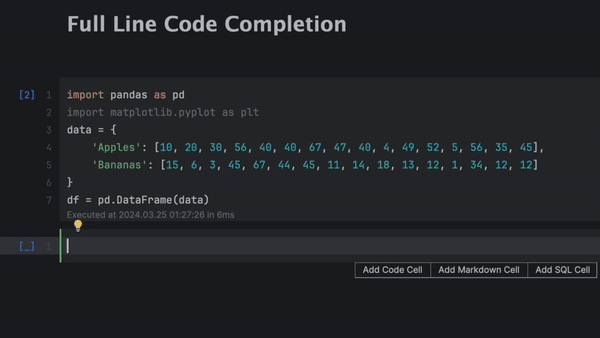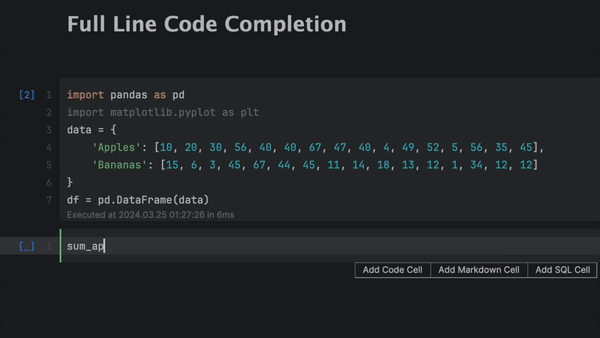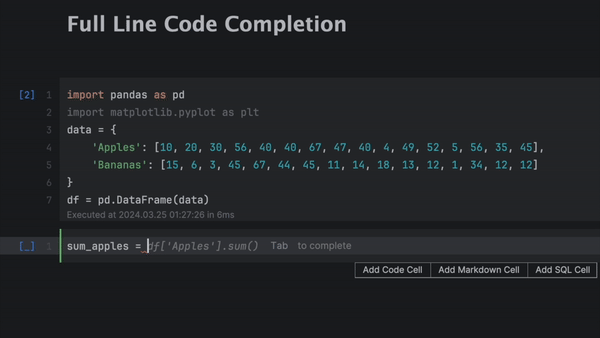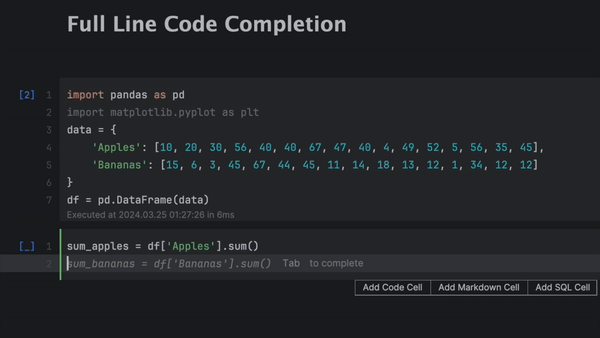
JetBrains a amélioré le modèle de machine learning local utilisé pour la saisie semi-automatique de code sur une ligne entière pour Python, offrant ainsi des suggestions plus longues avec davantage de contexte pris en compte, le tout sans envoyer de données sur Internet et entièrement gratuitement.
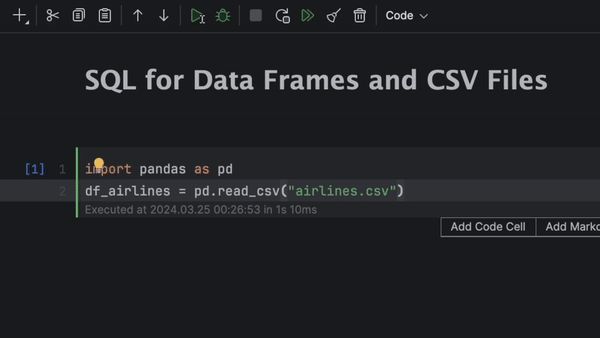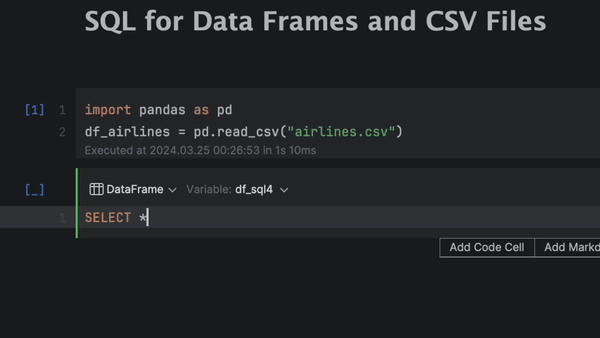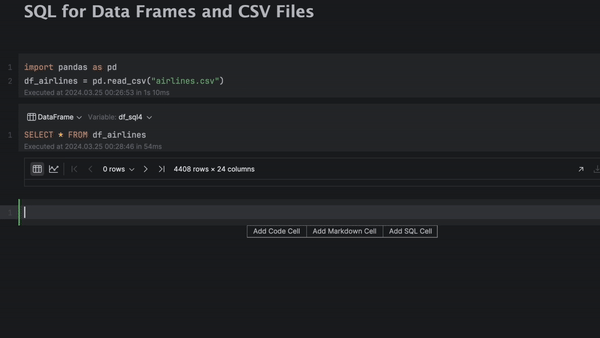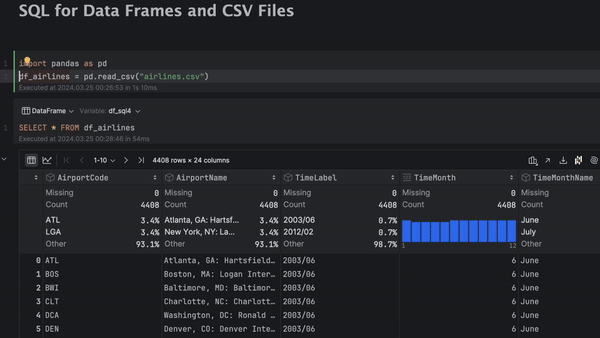
Dans DataSpell 2024.1, vous pouvez maintenant écrire du code SQL pour interroger des trames de données et des fichiers CSV directement dans vos notebooks Jupyter. JetBrains inaugure les cellules Import Data, un nouveau type de cellule dans DataSpell. Vous pouvez facilement commencer à travailler avec des données tabulaires en y déposant un fichier.
Cette dernière mise à jour améliore considérablement la prise en charge de dbt Core. Vous pouvez désormais afficher les graphiques directement dans DataSpell. JetBrains a amélioré la saisie semi-automatique du code pour les projets dbt Core et vous pouvez à présent exécuter, prévisualiser et tester des modèles directement à partir du fichier SQL.
Vous pouvez télécharger la nouvelle version de DataSpell à partir du site web officiel, mettre votre version à jour directement depuis l'EDI ou via l'application gratuite Toolbox App. Vous pouvez également utiliser des paquets snap pour Ubuntu.
Nous présentons dans la suite les principales nouveautés et améliorations avec plus de détails.
Saisie semi-automatique du code assistée par machine learning (ML)
L'équipe ML de JetBrains a considérablement amélioré le modèle local utilisé pour la saisie semi-automatique de ligne de code assistée par ML pour Python. La saisie semi-automatique de lignes de code génère des suggestions plus longues et élargit le contexte pris en compte, ce qui améliore les suggestions et réduit donc la saisie. En tant que modèle purement local, elle suggère des lignes de code entières sans envoyer de données à un serveur externe.
SQL pour les trames de données et les fichiers CSV
Dans DataSpell 2024.1, vous pouvez écrire du code SQL pour interroger des trames de données et des fichiers CSV directement à partir de votre notebook Jupyter. Pour cela, créez une cellule SQL, indiquez une trame de données comme source de données, puis écrivez une requête à laide de l'assistance au codage SQL la plus performante de sa catégorie.
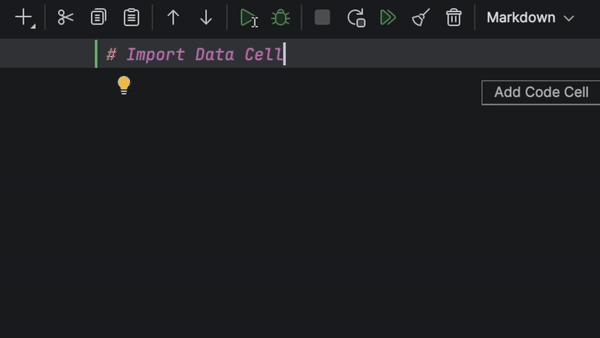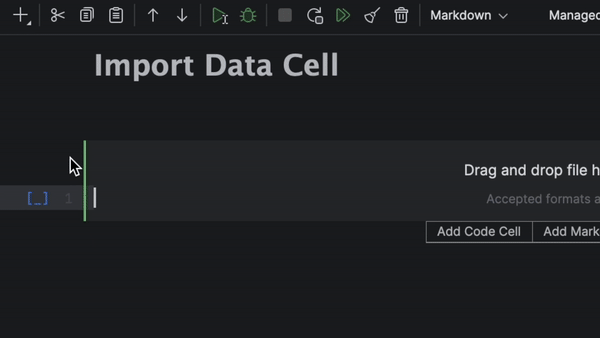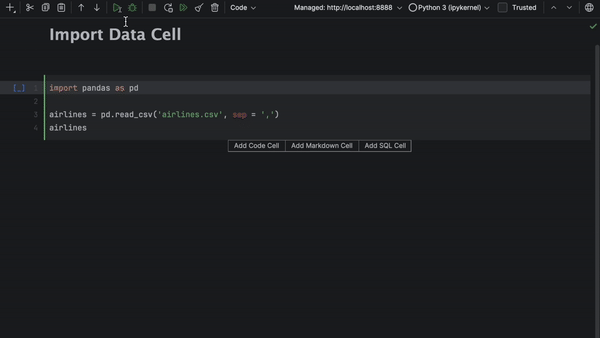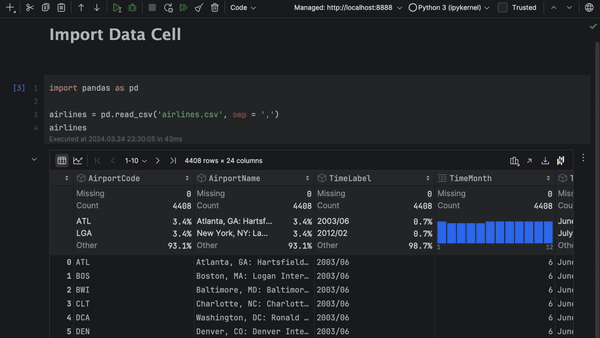
Cellules Import Data
Autre nouvelle fonctionnalité des notebooks Jupyter dans DataSpell 2024.1 : les cellules Import Data. Déposez simplement un fichier contenant des données tabulaires dans une cellule Import Data et travaillez sur ce fichier à l'aide de contrôles visuels ou de code Python.
dbt Core
La dernière version introduit plusieurs nouveautés pour la prise en charge de dbt :
Les DAG (Directed Acyclic Graph) sont de puissants outils pour les ingénieurs analytiques, et cette version vous permet dafficher les graphiques directement dans DataSpell. JetBrains a également facilité la navigation ; il vous suffit de cliquer sur les nuds dans le DAG.
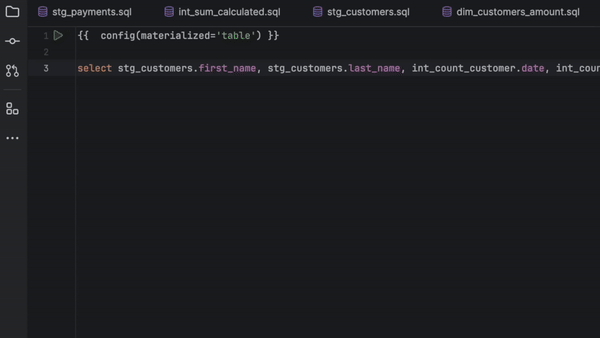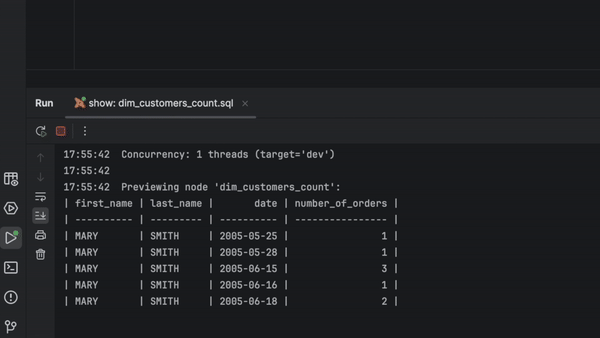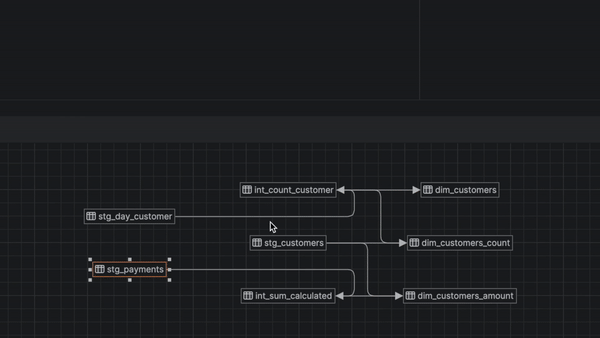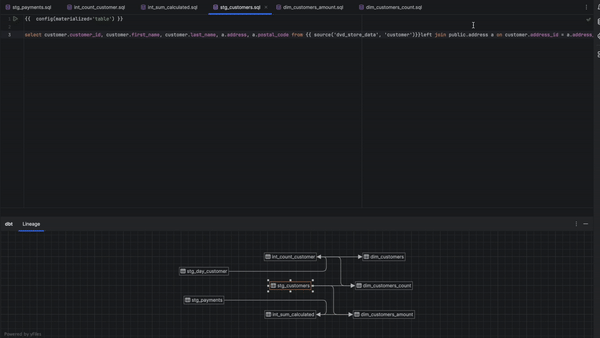
La saisie semi-automatique du code pour les projets dbt Core a été considérablement améliorée, notamment pour Jinja, les noms de modèles, les noms de colonnes, les fichiers YAML, et plus encore.
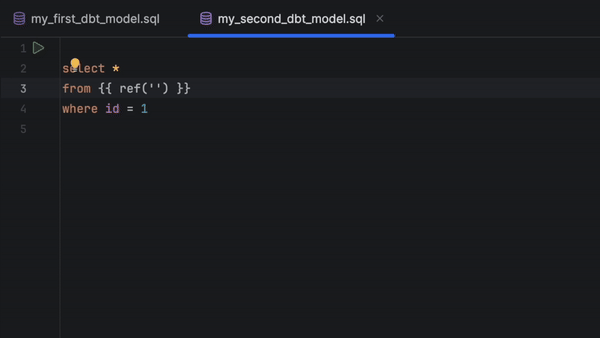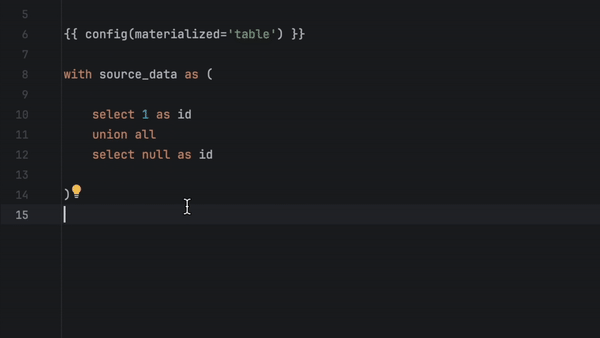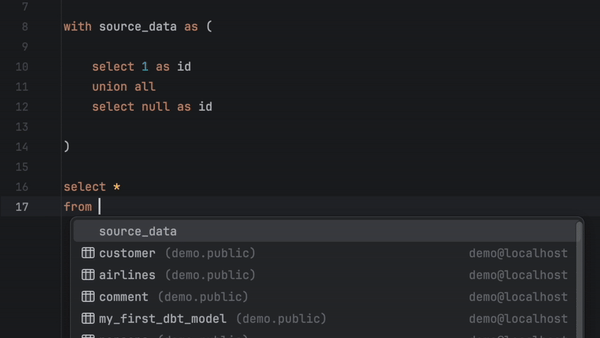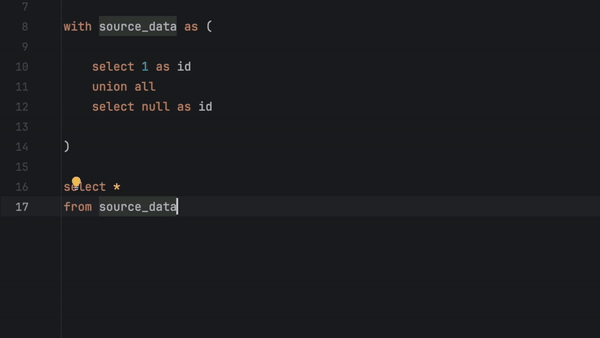
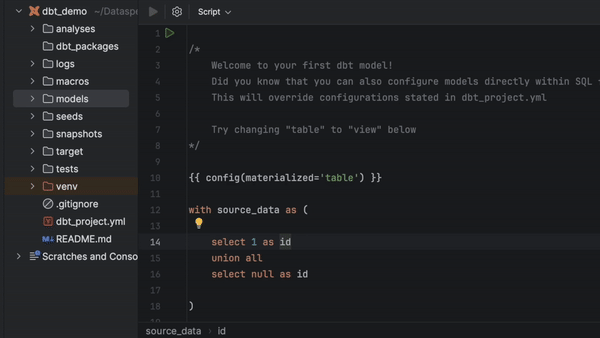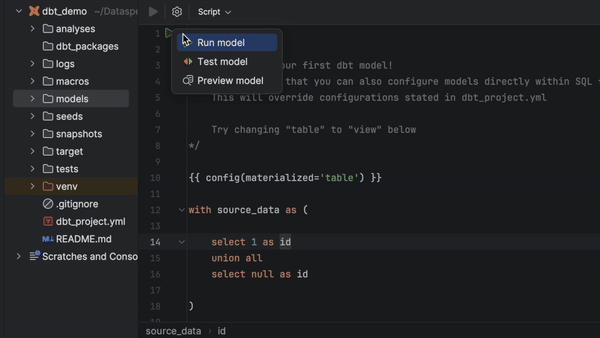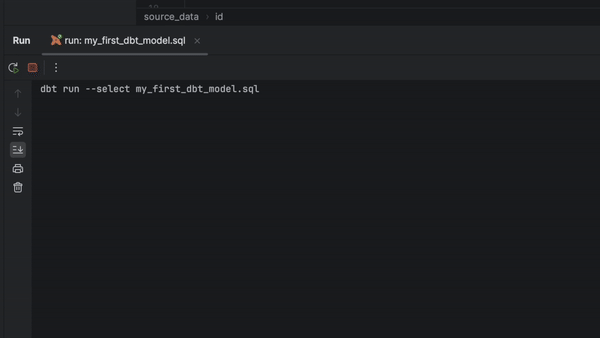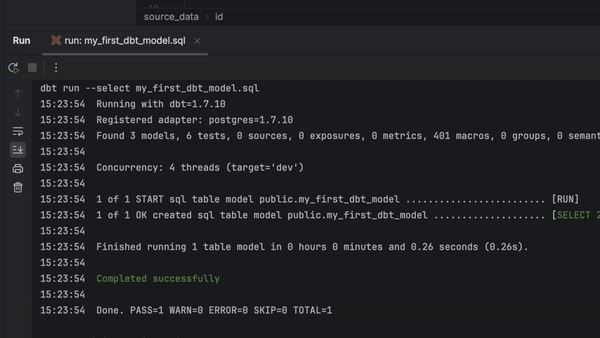
Vous pouvez à présent exécuter, prévisualiser et tester n'importe quel modèle directement à partir du fichier SQL. Il suffit de cliquer dans la gouttière et de choisir parmi les options disponibles.
 Nouveautés et téléchargement de DataSpell 2024.1
Nouveautés et téléchargement de DataSpell 2024.1
Vous avez lu gratuitement 17 234 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.