

 DataGrip 2024.1 est disponible :
DataGrip 2024.1 est disponible :Aperçu des améliorations de l'EDI de JetBrains pour les développeurs SQL
JetBrains annonce la sortie de DataGrip 2024.1. Il s'agit de la première mise à jour majeure de 2024 pour son EDI destiné aux administrateurs de bases de données et développeurs SQL. Cette version apporte un bon lot de nouveautés et améliorations dans divers domaines. Nous les présentons dans la suite avec plus de détails.
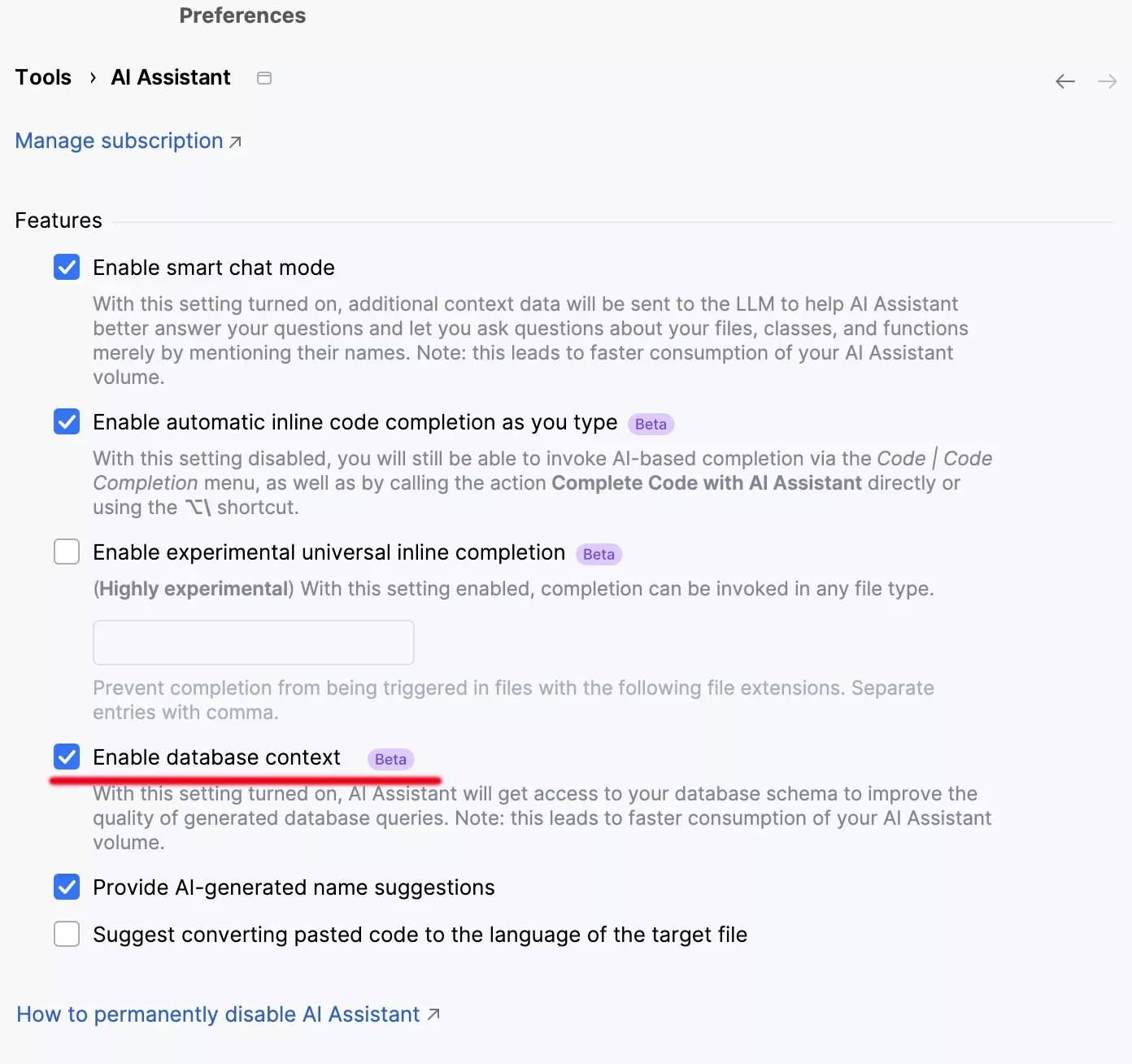
AI Assistant : possibilité d'attacher des schémas (DataGrip uniquement)
L'AI Assistant permet d'améliorer la qualité des requêtes SQL générées en attachant un schéma de base de données pour donner du contexte au chat. Pour l'instant, seuls les noms de table et de colonne sont attachés, et la limite est fixée à 50 tables.
Pour utiliser cette fonctionnalité, vous devez autoriser l'AI Assistant à rechercher des objets de base de données dans votre projet.
Vous pouvez faire cela à chaque fois que vous attachez un nouveau schéma, ou simplement cocher l'option Attach Schema dans la fenêtre contextuelle pour autoriser l'AI Assistant à mémoriser votre choix. Dans ce cas, le paramètre Enable database context est activé automatiquement.
Important : si le paramètre Enable database context est coché, l'AI Assistant aura accès à tous les noms d'objet en provenance de toutes les sources de données.
Les fonctionnalités accessibles depuis un menu contextuel dans l'éditeur, telles que Explain Code, comprennent désormais le schéma actif lorsqu'il est appelé depuis les consoles de base de données.
Parce que l'AI Assistant tient compte de votre schéma, vous pouvez :
- Générer des requêtes à partir de demandes en langage naturel.
- Obtenir des informations sur vos schémas.
- Réaliser des recherches poussées.
Et ce n'est qu'un aperçu de ce que vous pouvez faire. Les possibilités sont infinies !
Travailler avec des données
Filtre local dans l'éditeur de données
Une fonctionnalité très attendue est enfin disponible : vous pouvez désormais filtrer les lignes selon les valeurs des colonnes.
Cette méthode est rapide, car elle n'implique pas d'envoi de requête à la base de données. Toutefois, il est utile de noter que le filtre affecte uniquement la page active. Par conséquent, si vous voulez filtrer davantage d'informations, vous pouvez simplement agrandir la page ou récupérer toutes les données.
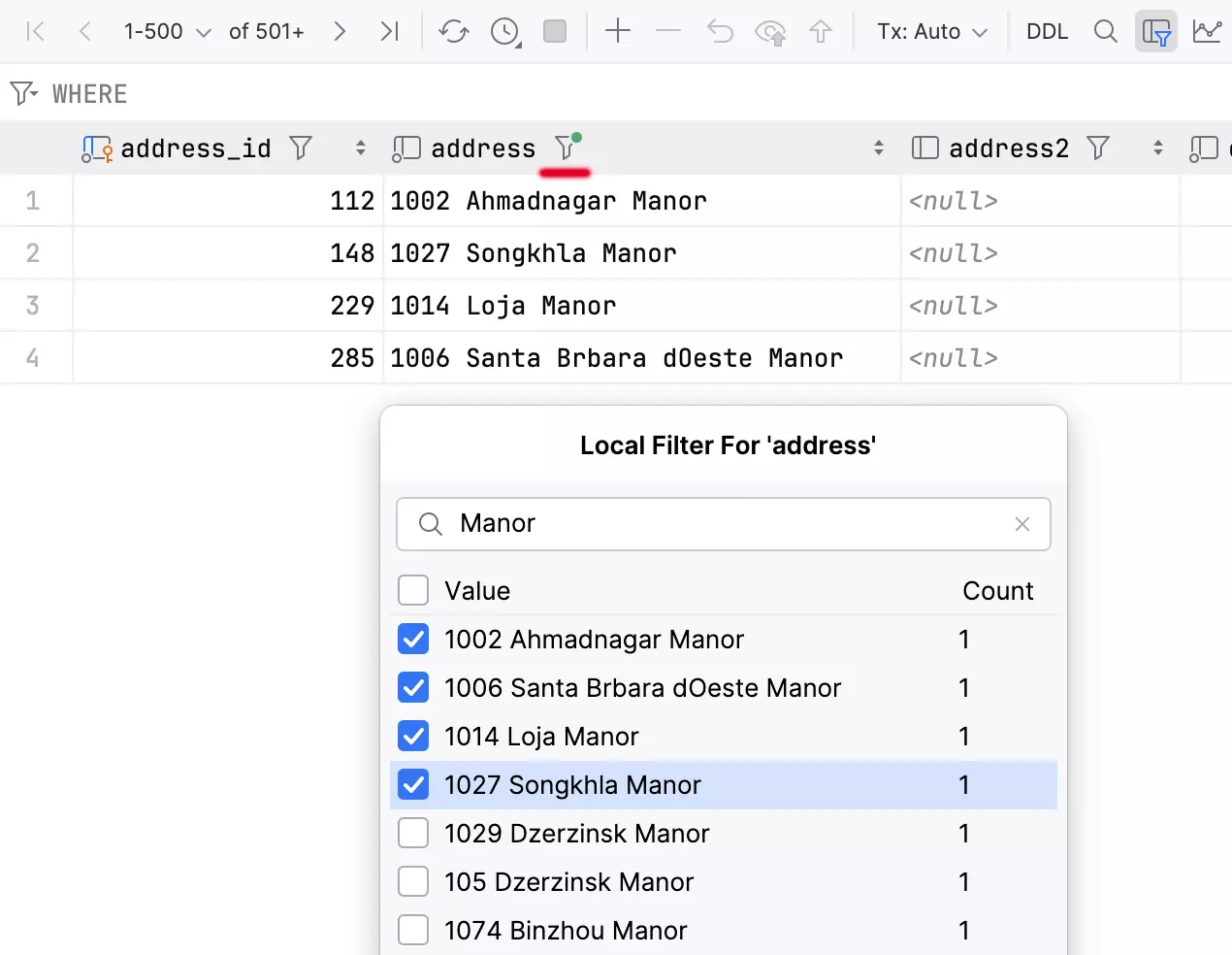
Si vous souhaitez désactiver l'ensemble des filtres locaux pour l'éditeur de données actuel, désactivez le bouton Enable Local Filter.
N'oubliez pas non plus la fonctionnalité locale de recherche de texte (Ctrl/Cmd+F) ! Elle existe depuis des décennies et reste toujours d'actualité, surtout si vous avez une idée de l'emplacement des données que vous recherchez.
Affichage d'un seul enregistrement
Il est désormais possible de se focaliser sur un seul enregistrement dans l'éditeur de données. Pour afficher un enregistrement spécifique, utilisez le raccourci Ctrl/Cmd+Maj+Entrée ou le bouton Show Record View de la barre d'outils.
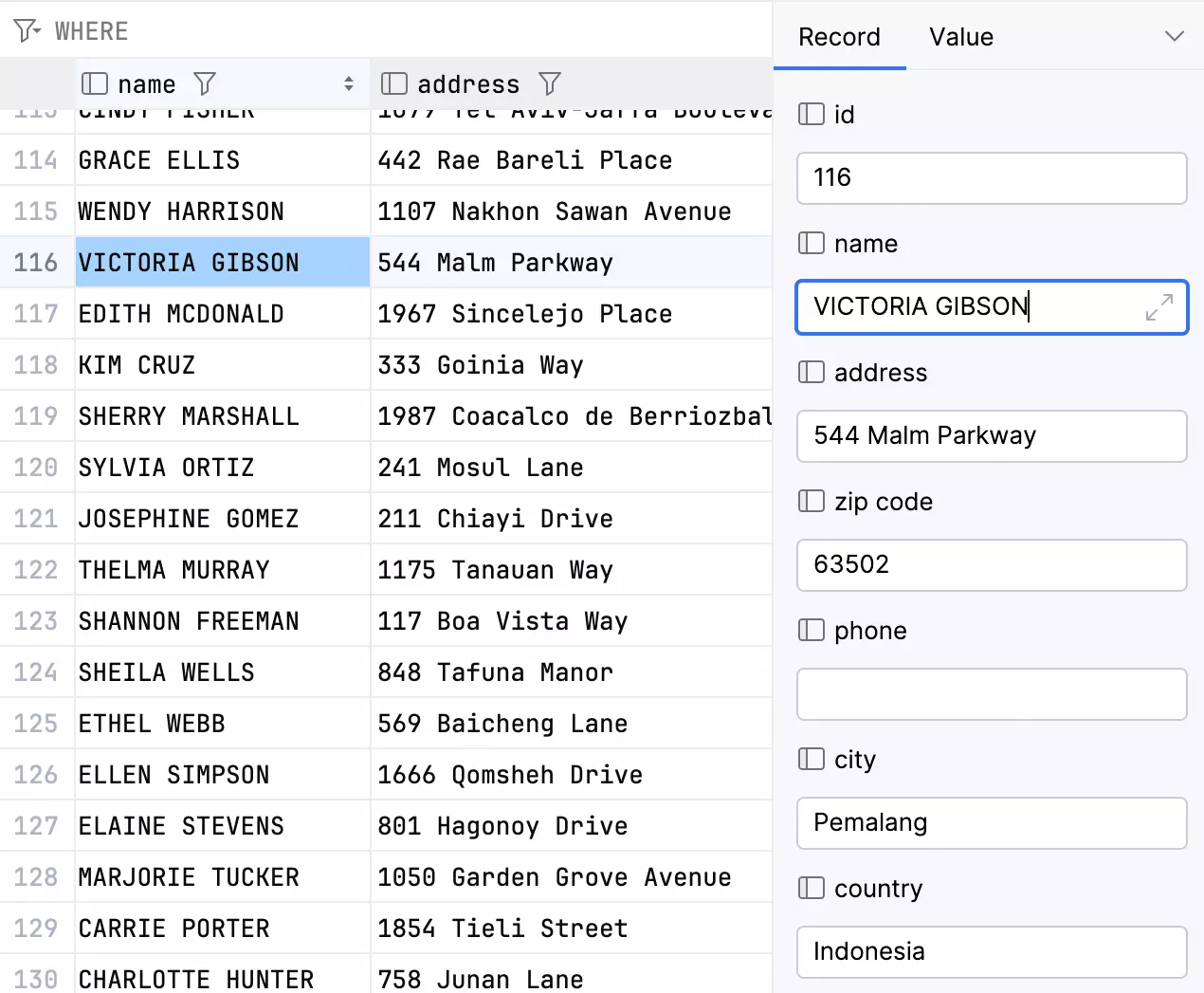
Les cellules de l'affichage d'enregistrement unique restent modifiables si elles le sont déjà dans la grille principale.
Vous pouvez également modifier la disposition pour utiliser deux colonnes si cela correspond à vos cas d'utilisation.
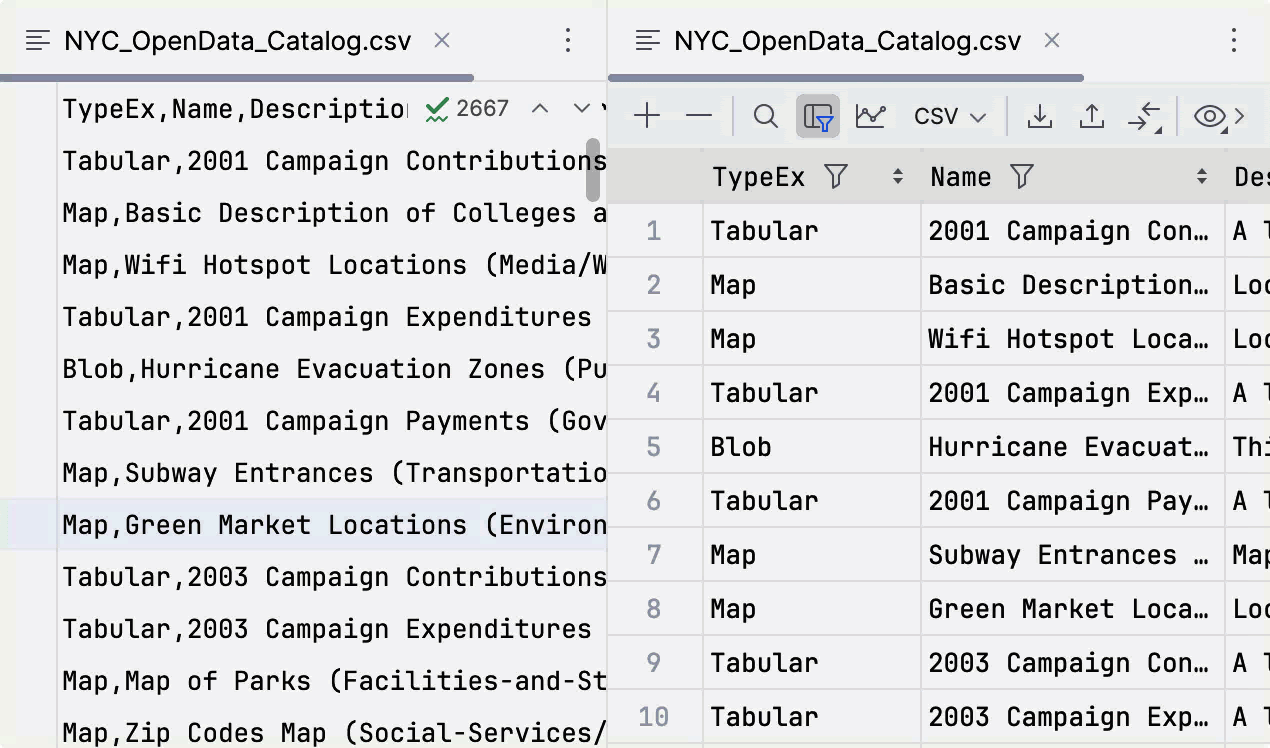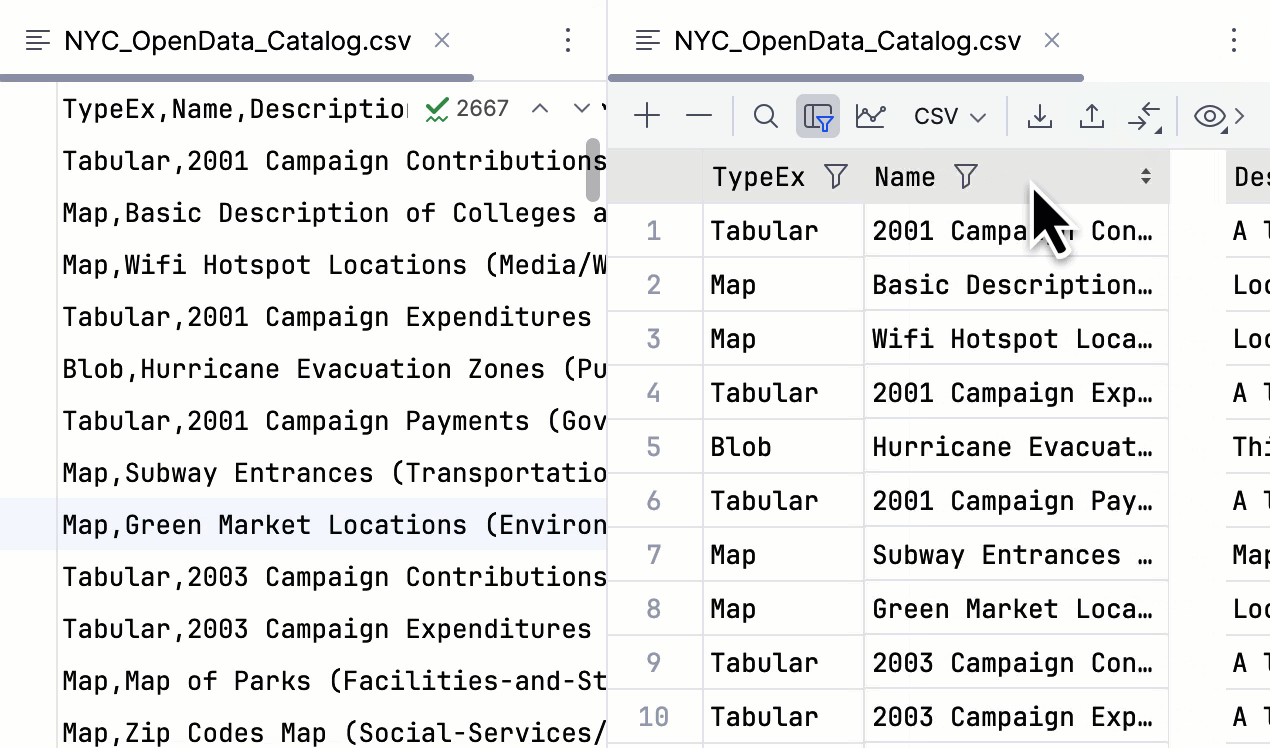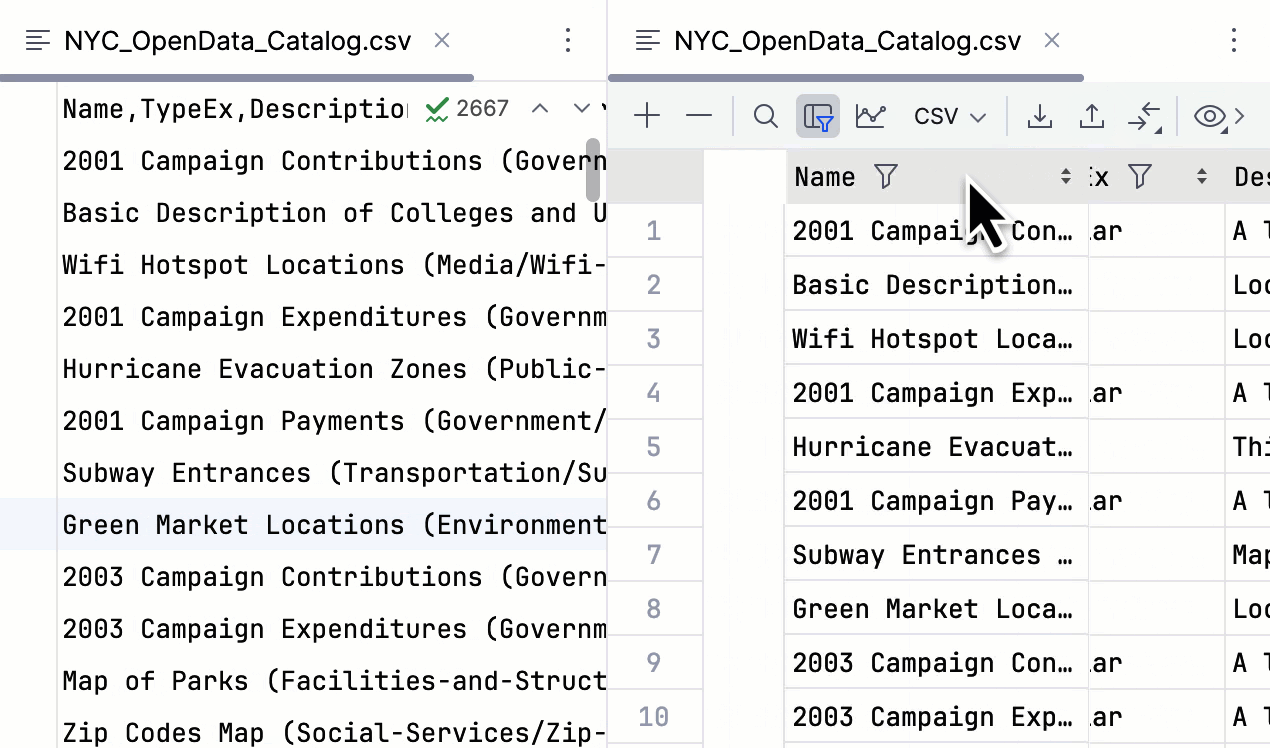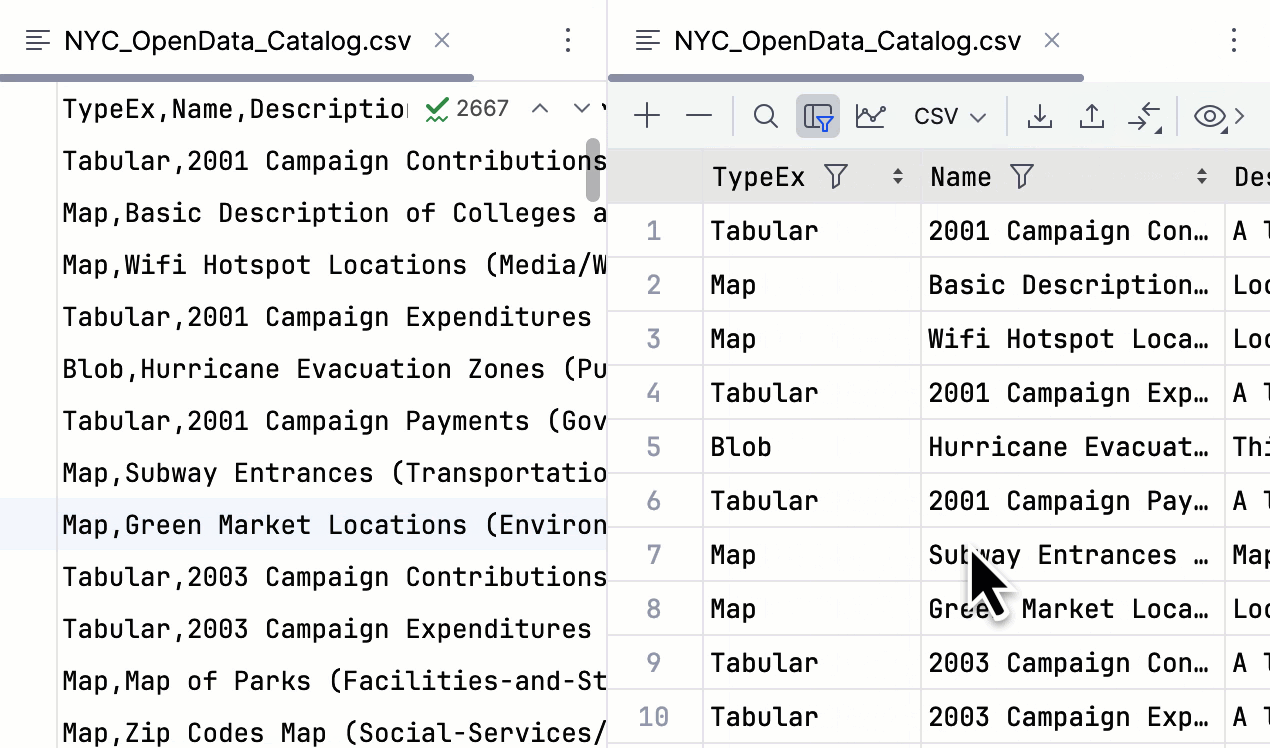
Possibilité de déplacer des colonnes dans les fichiers CSV
À partir de la version 2024.1, vous pouvez déplacer les colonnes d'un fichier CSV dans l'éditeur de données et appliquer ce changement au fichier.
Plus de fonctionnalités pour les UUID
En réponse à plusieurs tickets de son outil de suivi, JetBrains a facilité l'utilisation des UUID :
- JetBrains a ajouté la nouvelle action : Generate UUID.
- Il est désormais possible de modifier toutes les colonnes des UUID, y compris celles qui sont représentées par les types binary(16), blob(16) et similaires.
- Les valeurs des colonnes d'UUID peuvent désormais être validées en cours de modification (PostgreSQL).
Simplification des sessions
Au fil des dernières années, JetBrains a eu de très nombreux retours d'utilisateurs qui ne comprenaient pas le concept des sessions et trouvaient que cette fonctionnalité compliquait considérablement l'apprentissage de DataGrip. En voici quelques exemples :
Le modèle axé sur le projet et séparant la console et la session est vraiment trop lourd. L'ouverture et l'exécution d'un simple fichier SQL sont particulièrement pénibles. Pour simplement ouvrir et exécuter un script, je dois créer un projet, ajouter le fichier au projet, puis ouvrir une console, puis ouvrir une session et enfin attacher le fichier à la session. C'est vraiment trop.
Ayant utilisé précédemment SQL Server Management Studio, l'interface utilisateur de DataGrip me paraît beaucoup plus complexe. SSMS peut se résumer à des serveurs, des requêtes et des résultats. Dans DataGrip, il y a des sessions, des consoles, des fichiers temporaires, etc., etc., ce qui rend cet outil bien moins intuitif pour les nouveaux utilisateurs.
L'interface paraît parfois lourde et difficile à comprendre. Je ne comprends pas vraiment pourquoi il faut sélectionner une console pour exécuter un script, ni quelles sont les ramifications de la sélection. Cela ne devrait vraiment pas être le comportement par défaut.
La possibilité d'attacher des sessions est un mécanisme puissant, mais dans la majorité des cas, les utilisateurs doivent simplement définir le contexte (source de données et base de données ou schéma) d'exécution des requêtes.
À compter de la version 2024.1, les utilisateurs n'ont plus besoin de choisir manuellement dans quelle session exécuter les requêtes, quel que soit le type de requête. Les sessions existent toujours, mais vous n'aurez plus à vous en préoccuper. Nous allons voir plus en détail comment cette modification affecte les principaux cas d'utilisation de DataGrip.
Attachement et changement de sources de données
Pour joindre un fichier, il vous suffit maintenant de choisir la source de données plutôt que la session. Une fois la source de données sélectionnée, vous choisissez le schéma.
Changement de session
L'action Switch Session s'affiche désormais uniquement dans le menu contextuel du client, situé dans la fenêtre d'outils Services. Elle vous permet de changer la session uniquement dans la source de données active.
Exécution de fonctions
Il n'est plus nécessaire de sélectionner une session avant de lancer une fonction. Dans la fenêtre Execute Routine, l'option Run from vous permet de sélectionner la console ou le fichier devant servir au lancement de la fonction.
Travailler avec du code
Style de code aligné pour les instructions INSERT sur plusieurs lignes
Vous pouvez désormais formater les instructions INSERT sur plusieurs lignes afin que leurs valeurs soient alignées. Le formateur va analyser la largeur des valeurs dans chaque colonne et appliquer les largeurs optimales.
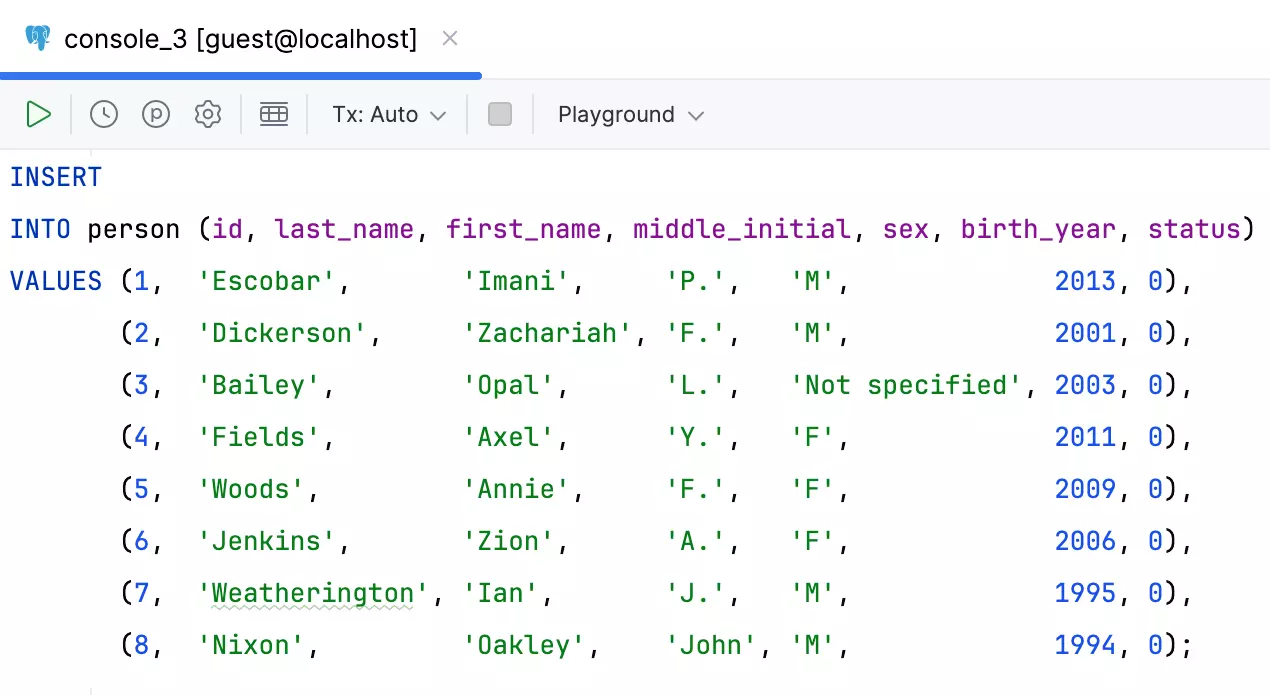
Pour utiliser cette fonctionnalité, activez l'option Align multi-row VALUES.
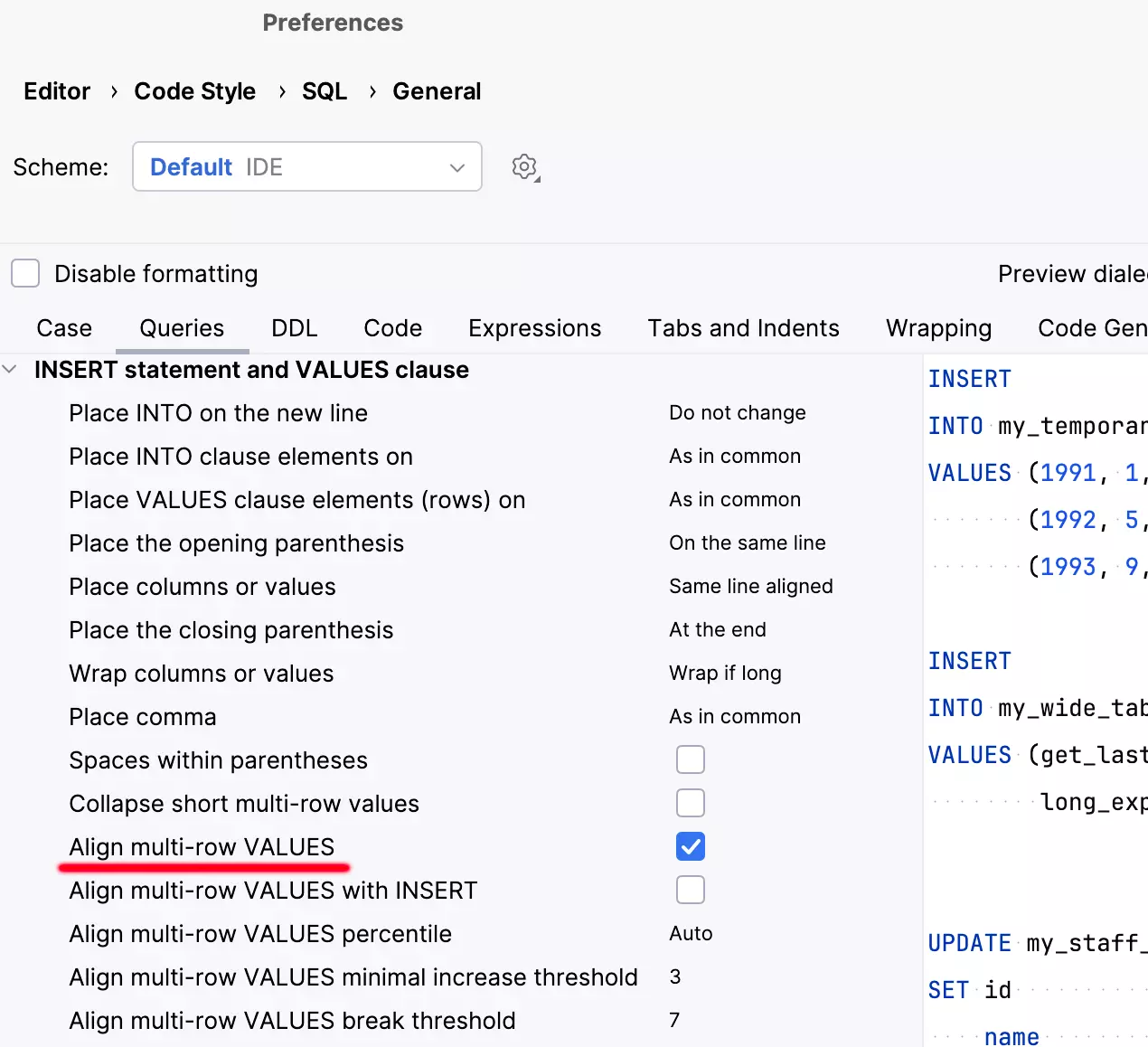
DataGrip est aussi capable de gérer les situations où certaines valeurs sont plus longues que d'autres. Le formateur détecte ces valeurs et crée des exceptions pour elles, puis déplace les champs restants sur la ligne suivante.
Saisie semi-automatique de la colonne pour les clauses GROUP BY
DataGrip analyse désormais les agrégats utilisés dans les clauses SELECT et inclut les listes de colonnes appropriées dans les suggestions de clauses GROUP BY.
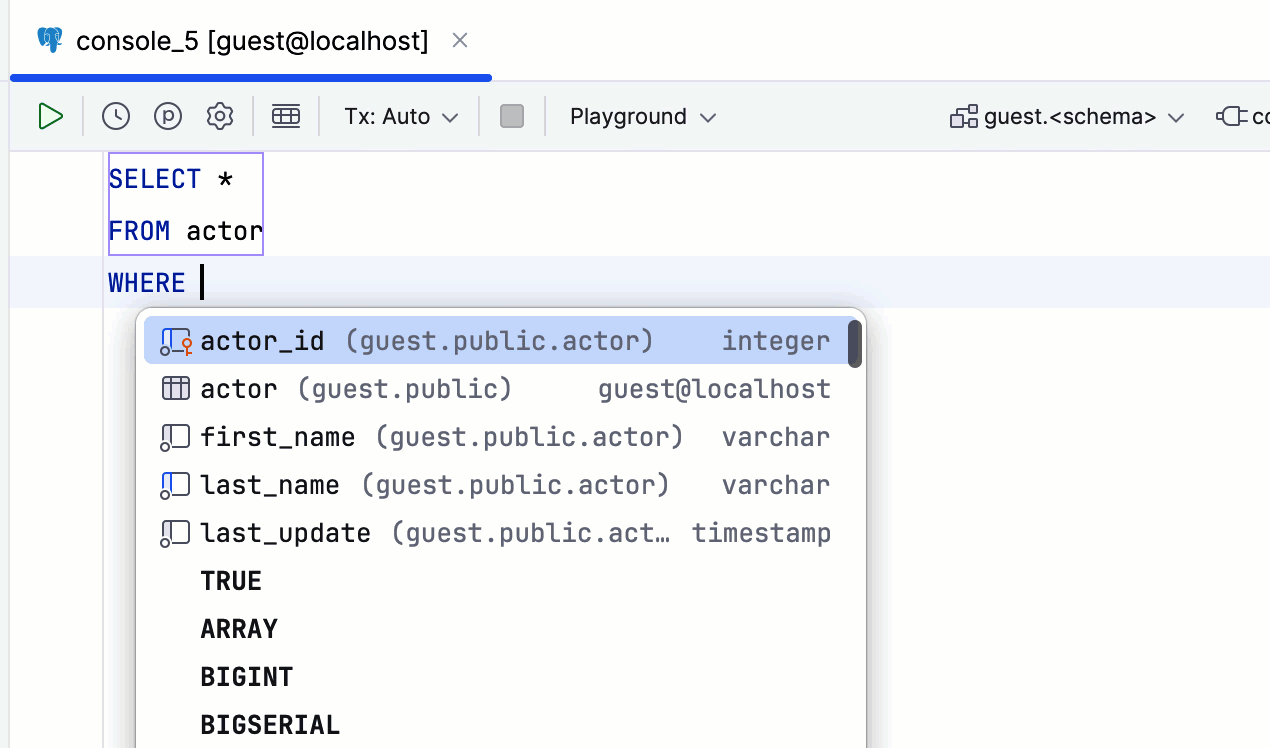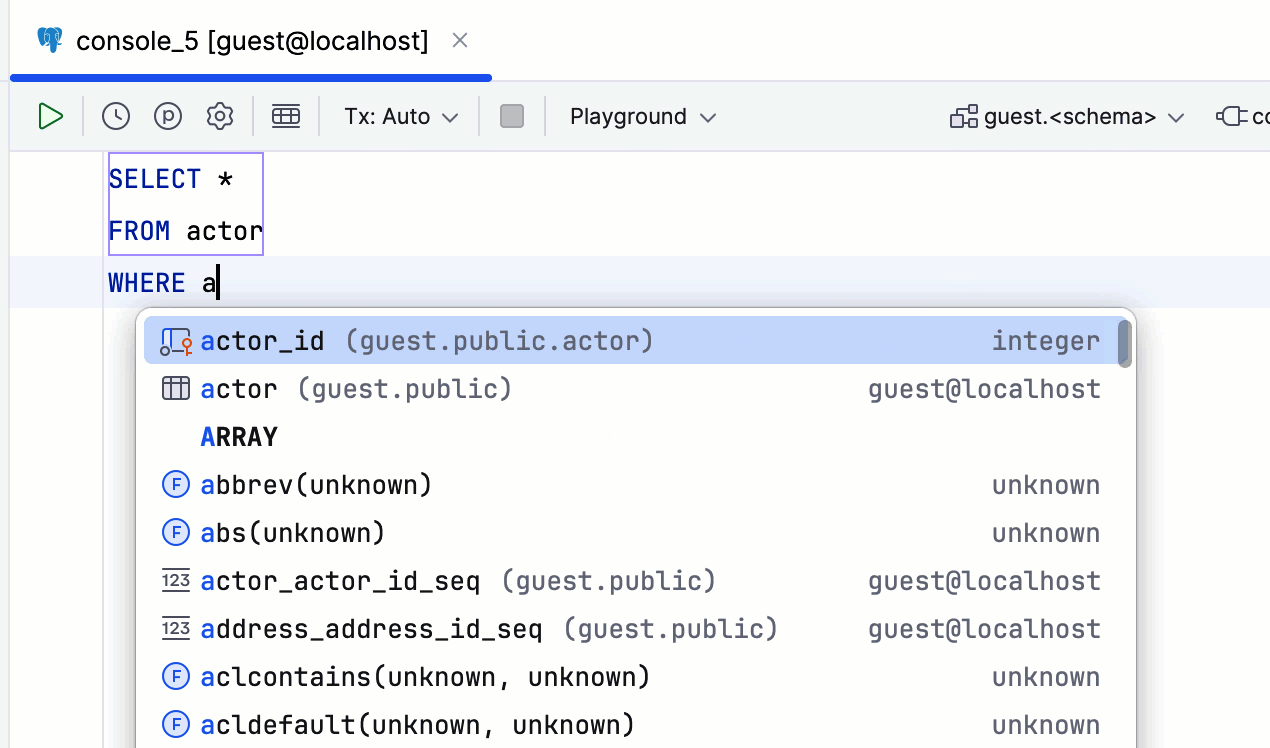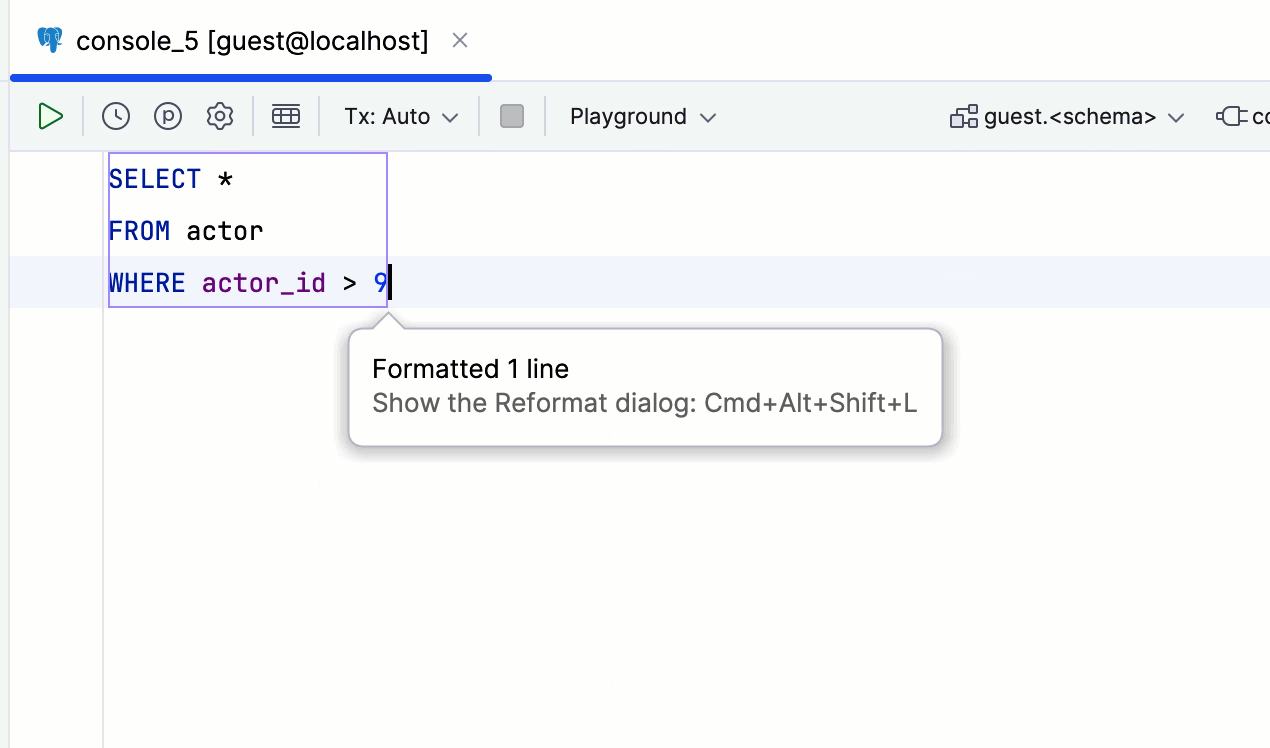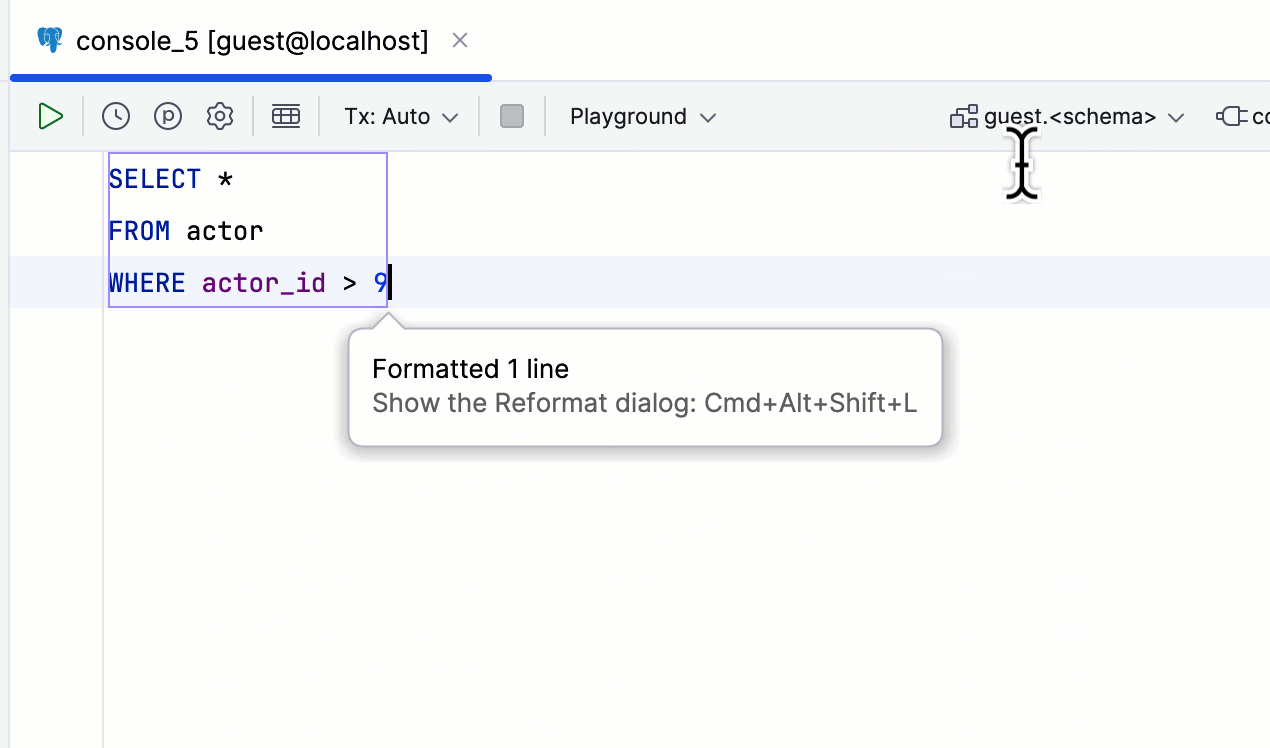
Avertissement pour les clauses WHERE TRUE
JetBrains a élargi son avertissement Unsafe query. Il vous prévient désormais si vous exécutez une requête avec la condition WHERE TRUE ou l'une de ses variations. Cela peut être vital si vous aimez utiliser cette clause pour le débogage, mais oubliez parfois de la modifier.
Symboles personnalisés pour accepter les suggestions
JetBrains a ajouté la possibilité de spécifier quels symboles utiliser pour accepter les suggestions de saisie semi-automatique, vous permettant ainsi d'écrire du SQL encore plus rapidement.
Cette fonctionnalité peut être particulièrement utile lors de l'utilisation d'opérateurs.
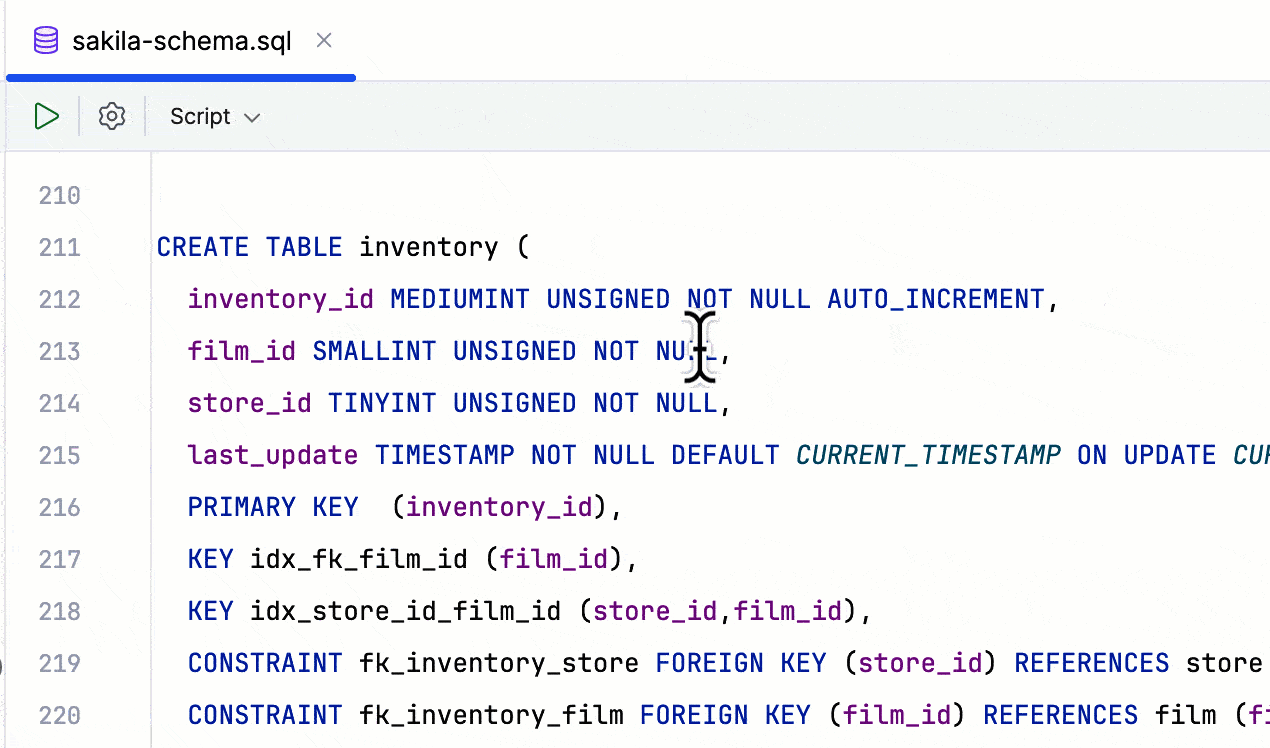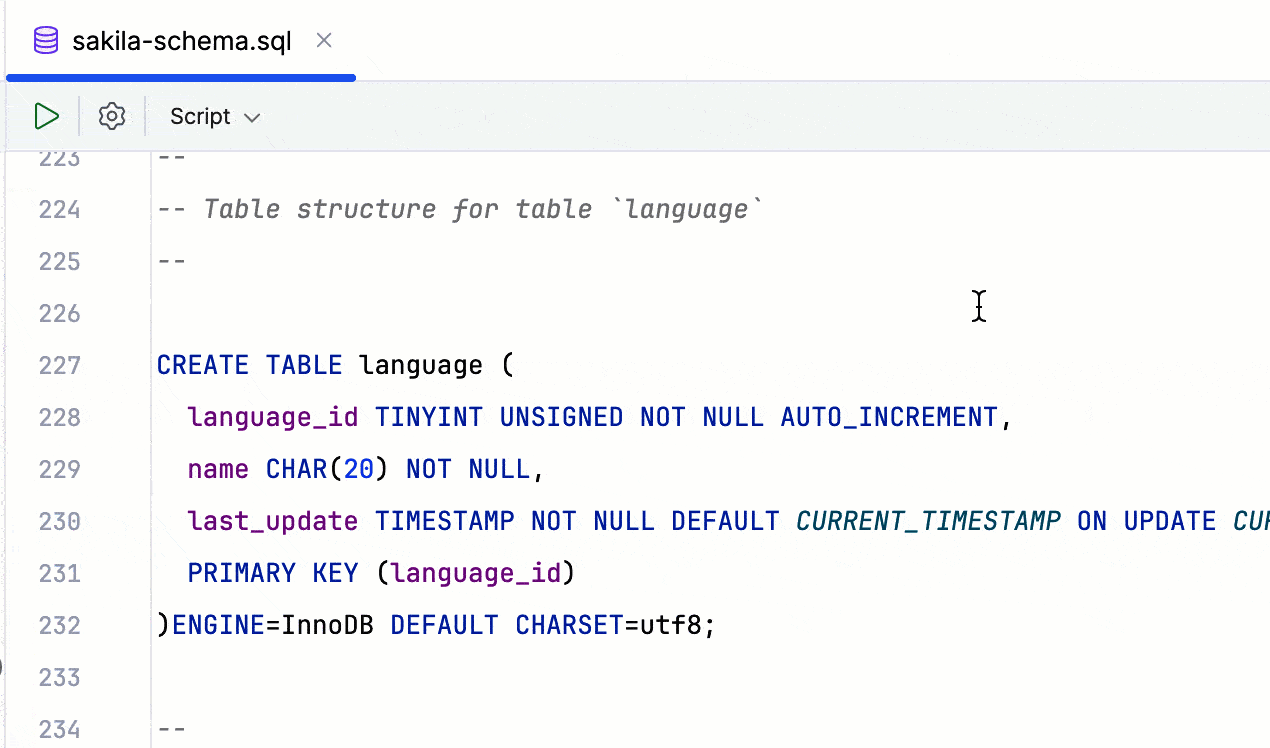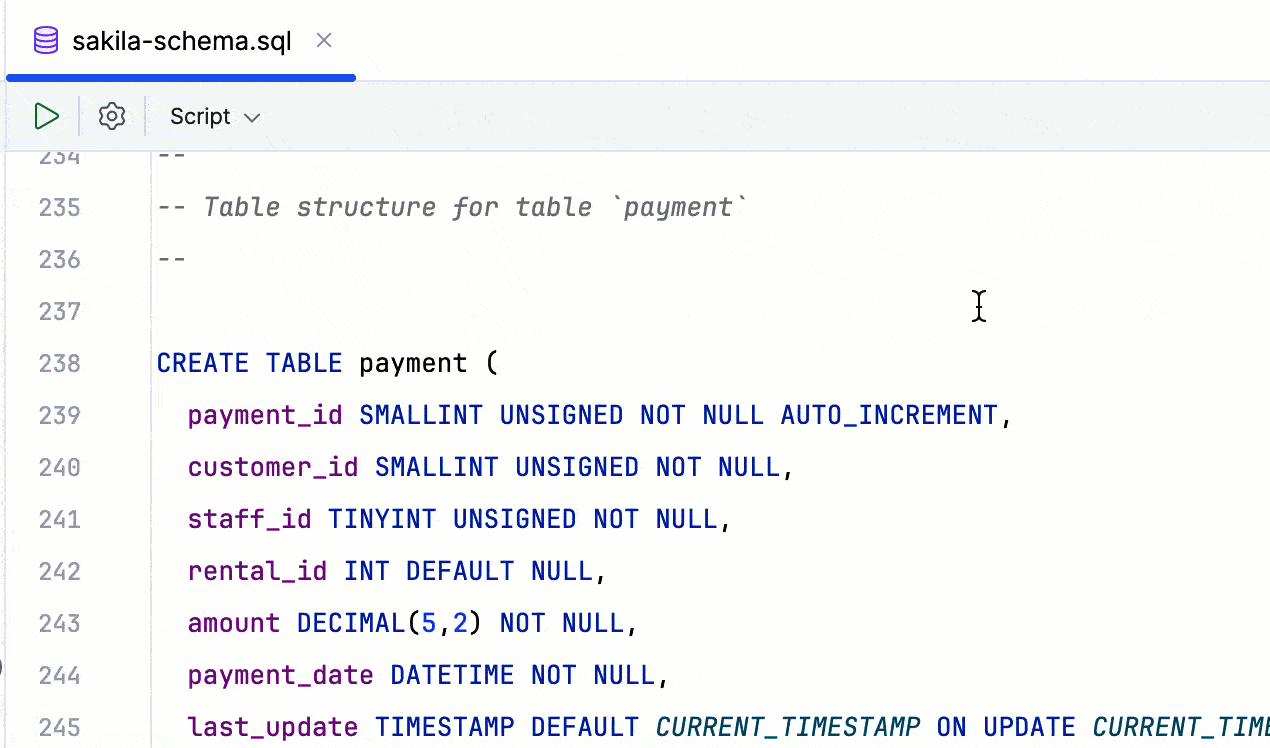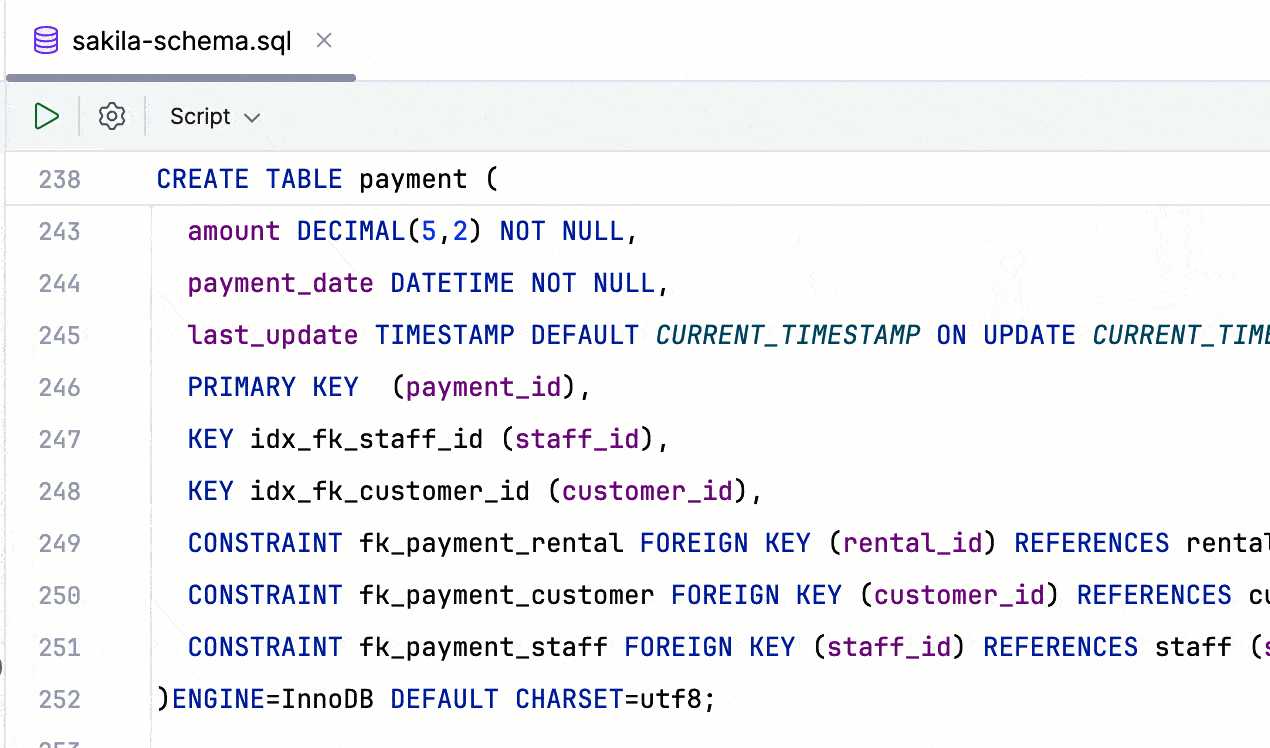
Lignes épinglées dans l'éditeur
Pour simplifier l'utilisation de fichiers volumineux, DataGrip 2024.1 inaugure les lignes épinglées dans l'éditeur. Cette fonctionnalité conserve des éléments structurels clés, tels que les instructions CREATE, épinglés en haut de l'éditeur pendant que vous faites défiler l'écran. Le contexte reste ainsi toujours visible et vous pouvez naviguer rapidement dans le code en cliquant sur une ligne épinglée.
Cette fonctionnalité est activée par défaut. Vous pouvez la désactiver via la case à cocher Settings/Preferences | Editor | General | Appearance, qui permet également de définir le nombre maximum de lignes épinglées.
Autres améliorations
Prise en charge des commandes des modules de Redis Stack (Redis)
DataGrip prend désormais en charge les commandes des quatre principaux modules de Redis Stack : RedisJSON, RediSearch, RedisBloom et RedisTimeSeries. Cette prise en charge nécessite aussi la nouvelle version du pilote : v1.5. Le module RedisGraph est obsolète et ne sera plus pris en charge. La prise en charge du module présente les avantages suivants :
- Vous pouvez envoyer des commandes depuis ces modules et voir les résultats.
- Les commandes de ces modules sont mises en évidence correctement.
- Les clés des types fournis par ces modules s'affichent dans l'explorateur de base de données.
Documents JSON
Les documents JSON s'affichent désormais dans un dossier dédié. Vous pouvez afficher leur valeur dans le visualiseur de données, puis spécifier le chemin JSON.
Autres types de données
Les clés des types fournis par les modules RedisTimeSeries et RedisBloom s'affichent dans le dossier data structures.
Prise en charge des bases de données externes partagées via des catalogues de données (Amazon Redshift)
Les bases de données externes partagées via des catalogues de données ne sont pas prises en charge. Leur contenu fait désormais l'objet d'une introspection et la saisie semi-automatique y est disponible.
 Nouveautés et téléchargement de DataGrip 2024.1
Nouveautés et téléchargement de DataGrip 2024.1
Vous avez lu gratuitement 1 663 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.