

 DataGrip 2021.3 est disponible
DataGrip 2021.3 est disponibleL'EDI de JetBrains pour les développeurs SQL vient avec de nombreuses améliorations dans divers domaines
DataGrip 2021.3 est disponible. C'est la troisième grande mise à jour de 2021. Dans la version précédente, l'EDI de JetBrains destiné aux administrateurs de bases de données et développeurs SQL a apporté un bon lot d'améliorations. JetBrains continue dans la même lancée dans la version 2021.3 avec de nombreuses améliorations à différents niveaux : éditeur de données, bases de données dans le système de contrôle de version, connectivité, explorateur de données, console de requête, importation et exportation, etc. Nous présentons dans les suites ces nouveautés de manière détaillée.
Éditeur de données
Vue Aggregate
JetBrains a ajouté la possibilité d'afficher une vue Aggregate pour une plage de cellules. Cette fonctionnalité très attendue vous permettra de gérer vos données et vous épargnera l'écriture de requêtes supplémentaires. Cela rend l'éditeur de données encore plus puissant et simple d'utilisation, et le rapproche encore un peu plus d'Excel et des feuilles de calcul Google.
Sélectionnez la plage de cellules pour laquelle vous voulez afficher la vue, puis faites un clic droit et sélectionnez Show Aggregate View.
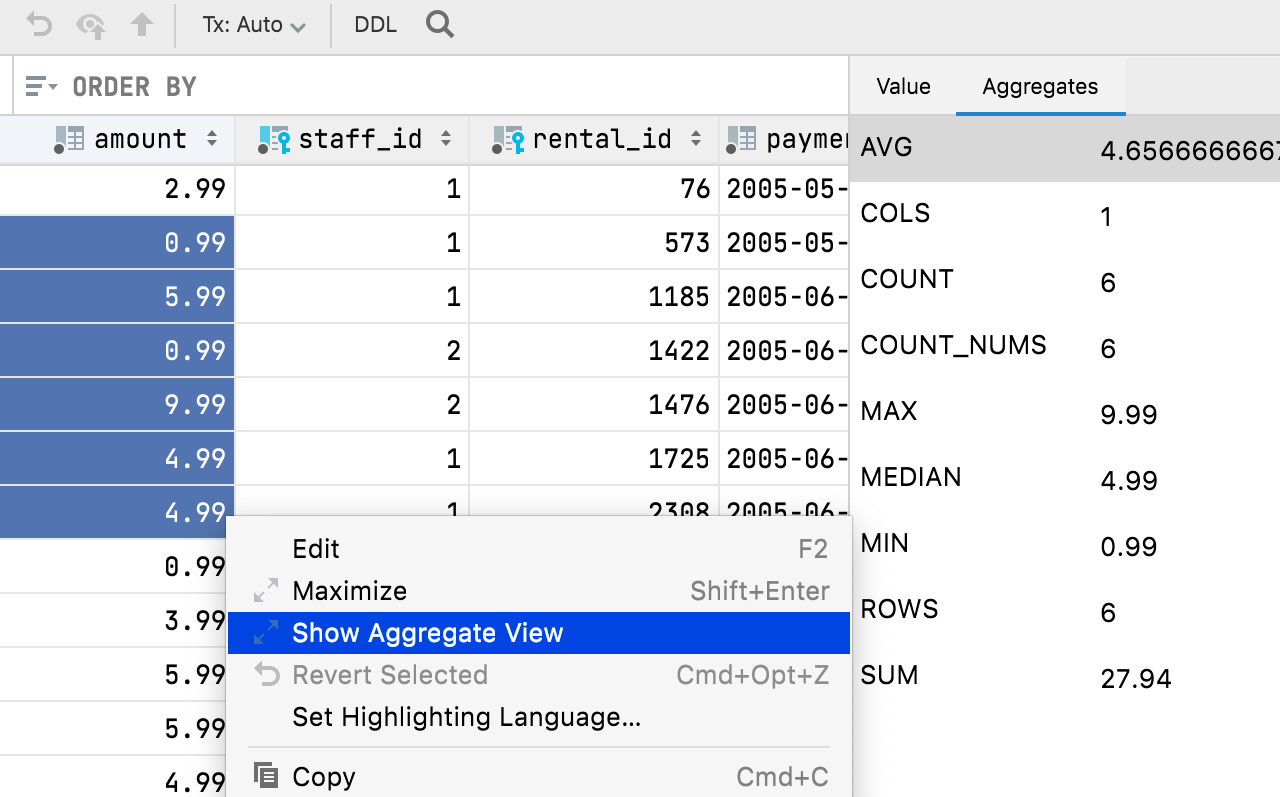
En résumé :
- La vue Aggregate s'affiche dans le même panneau que la vue Value, chacune ayant désormais son propre onglet. Vous pouvez déplacer ce panneau vers le bas de l'éditeur de données.
- L'icône engrenage permet d'afficher ou de masquer n'importe quel agrégat dans cette vue.
- Comme les extracteurs, les agrégats sont des scripts. Vous pouvez créer et partager les vôtres en complément des neuf scripts fournis par défaut.
- Les scripts d'agrégats et les extracteurs sont interchangeables. Si vous avez déjà utilisé un extracteur pour n'obtenir qu'une seule valeur, vous pouvez la copier dans le dossier Aggregators et l'utiliser pour les agrégats. Comme le dossier Extractors, vous le trouverez dans Scratches and consoles / Extensions / Database Tools and SQL.
- Une valeur d'agrégat s'affiche dans la barre d'état et vous pouvez en choisir le type (somme, moyenne, médiane, min, max, etc.).
Vue de table pour les nuds d'arborescence
Appuyer sur F4 sur n'importe quel nud de schéma permet d'afficher une vue de table du contenu du nud. Par exemple, vous pouvez obtenir une vue de table regroupant l'ensemble des tables du schéma. Vous pouvez également afficher une vue en tableau des colonnes d'une table.
Cette vue permet d'afficher/de masquer les colonnes, d'exporter les données en de nombreux formats et d'utiliser la recherche de texte. Mais surtout, les actions de navigation suivantes fonctionnent ici également :
- Ctrl+B affiche le DDL.
- F4 affiche les données.
- Alt+Maj+B met en évidence l'objet dans l'arborescence de la base de données.
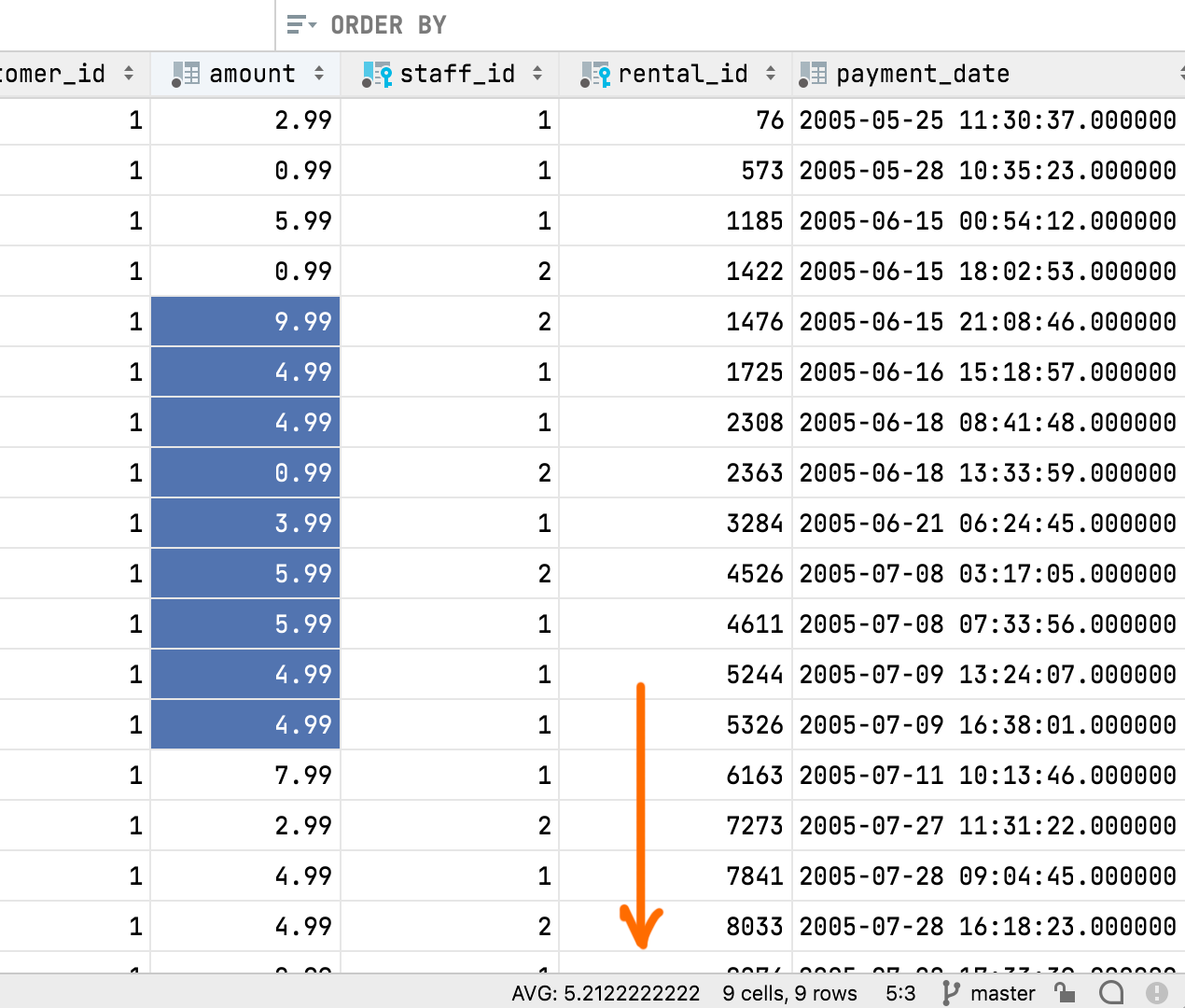
Fenêtres fractionnées indépendantes
Si vous divisez l'éditeur de données et l'ouvrez à nouveau dans la même table, ses deux fenêtres sont désormais totalement indépendantes l'une de l'autre. Vous pouvez appliquer les filtres et les options de tri nécessaires pour les comparer et travailler avec les données. Auparavant, le filtrage et le tri étaient synchronisés, ce qui était loin d'être idéal.
Police personnalisée
Vous pouvez choisir une police dédiée pour l'affichage des données dans la section Database | Data views | Use custom font.
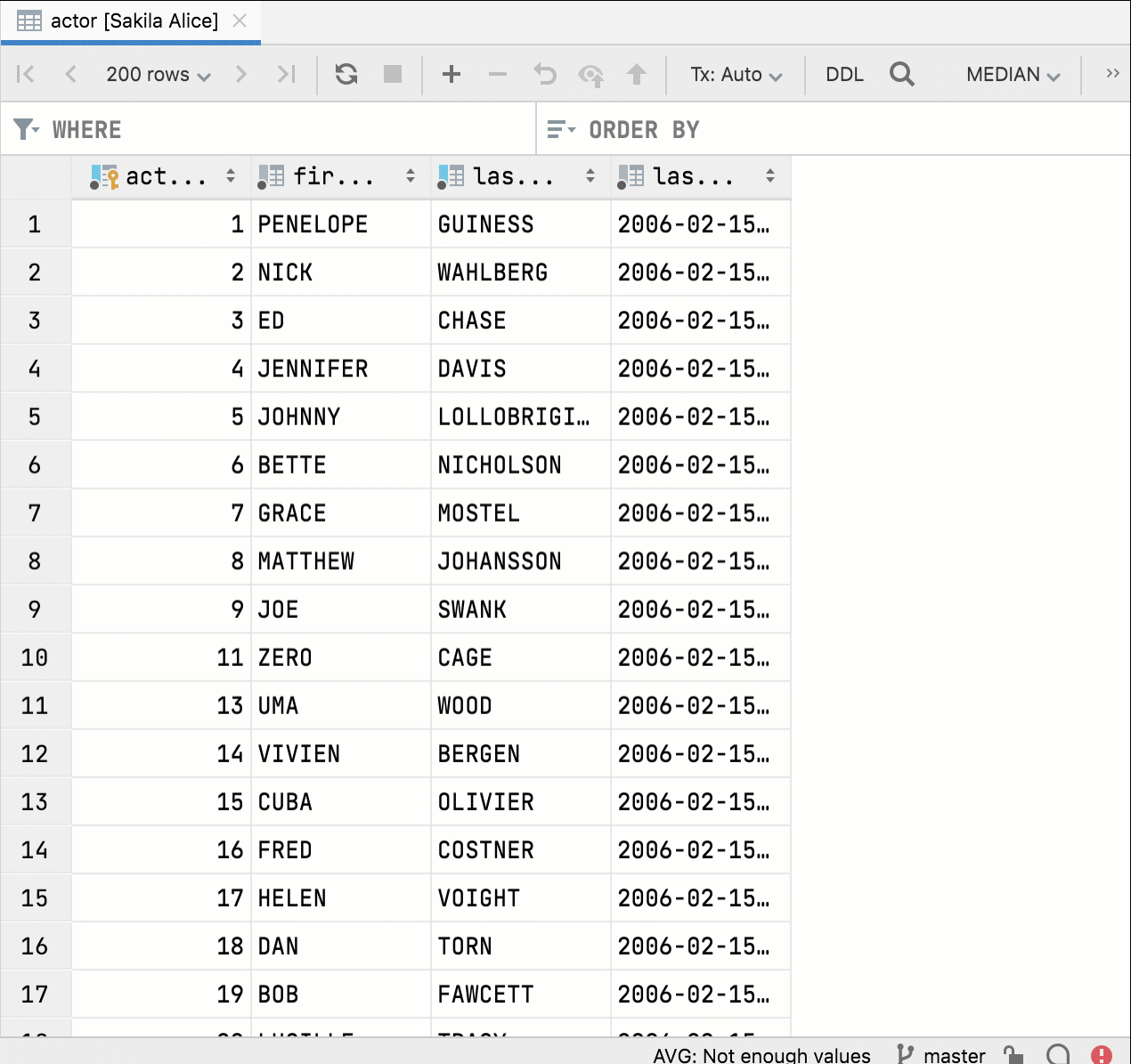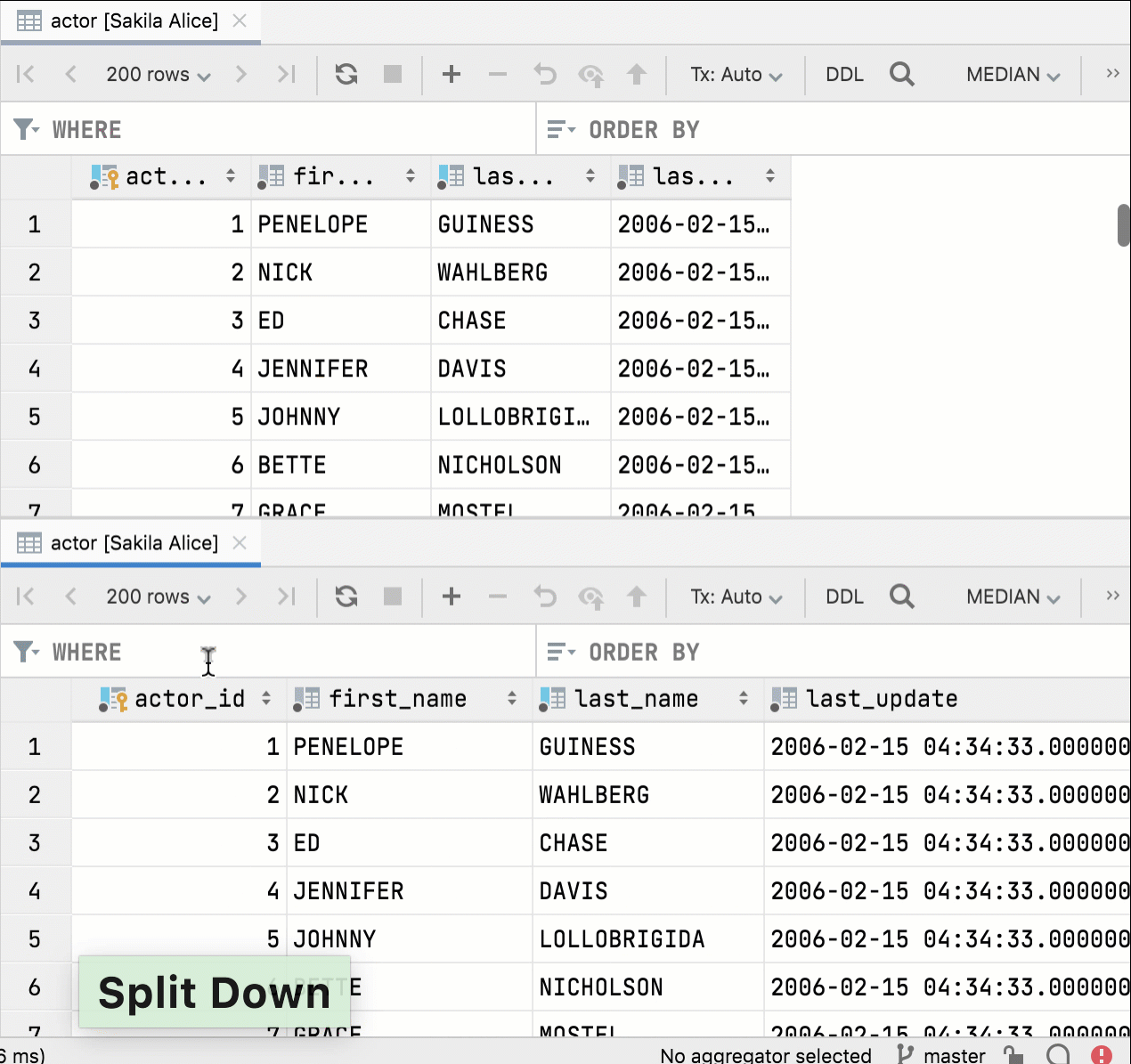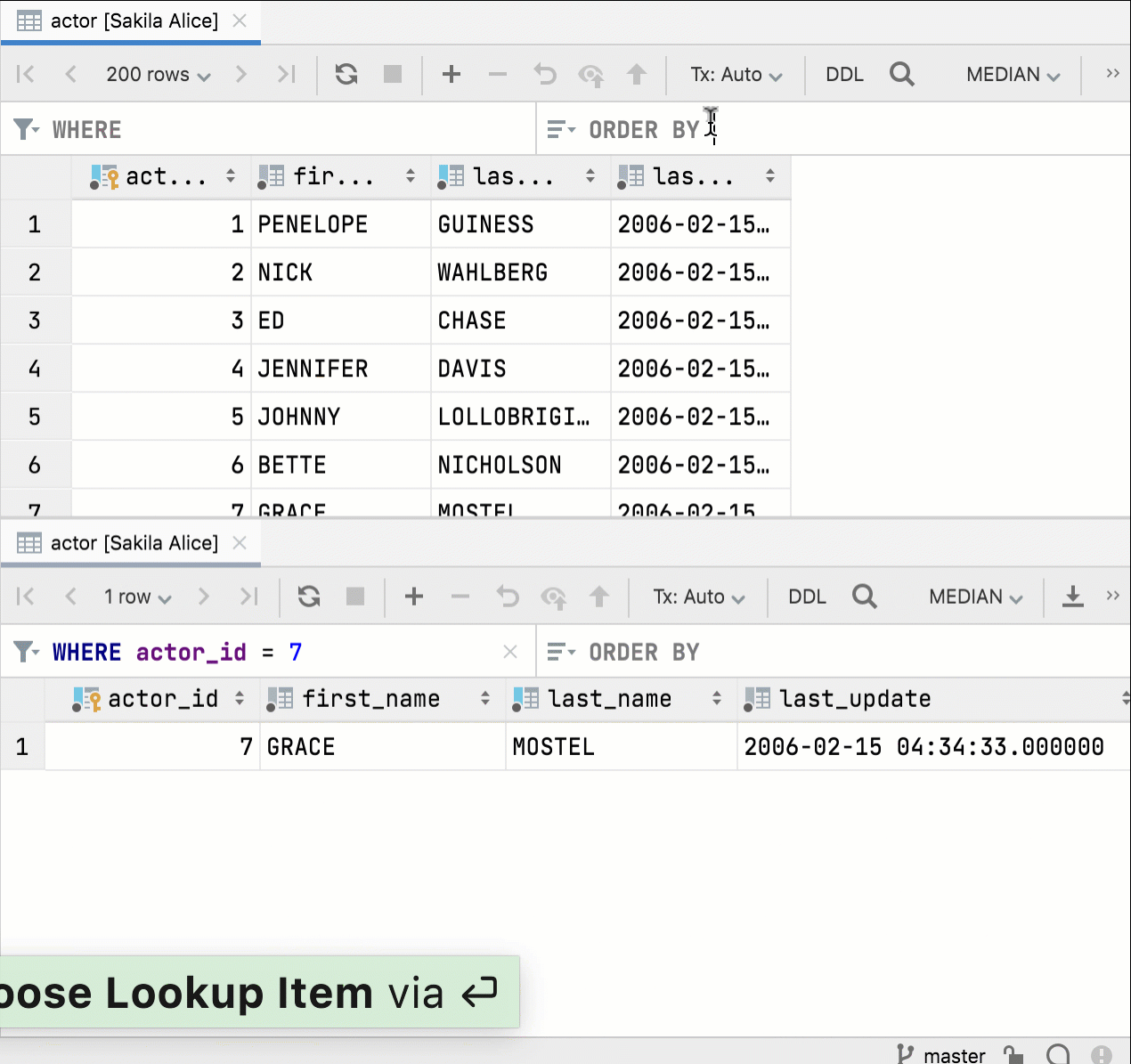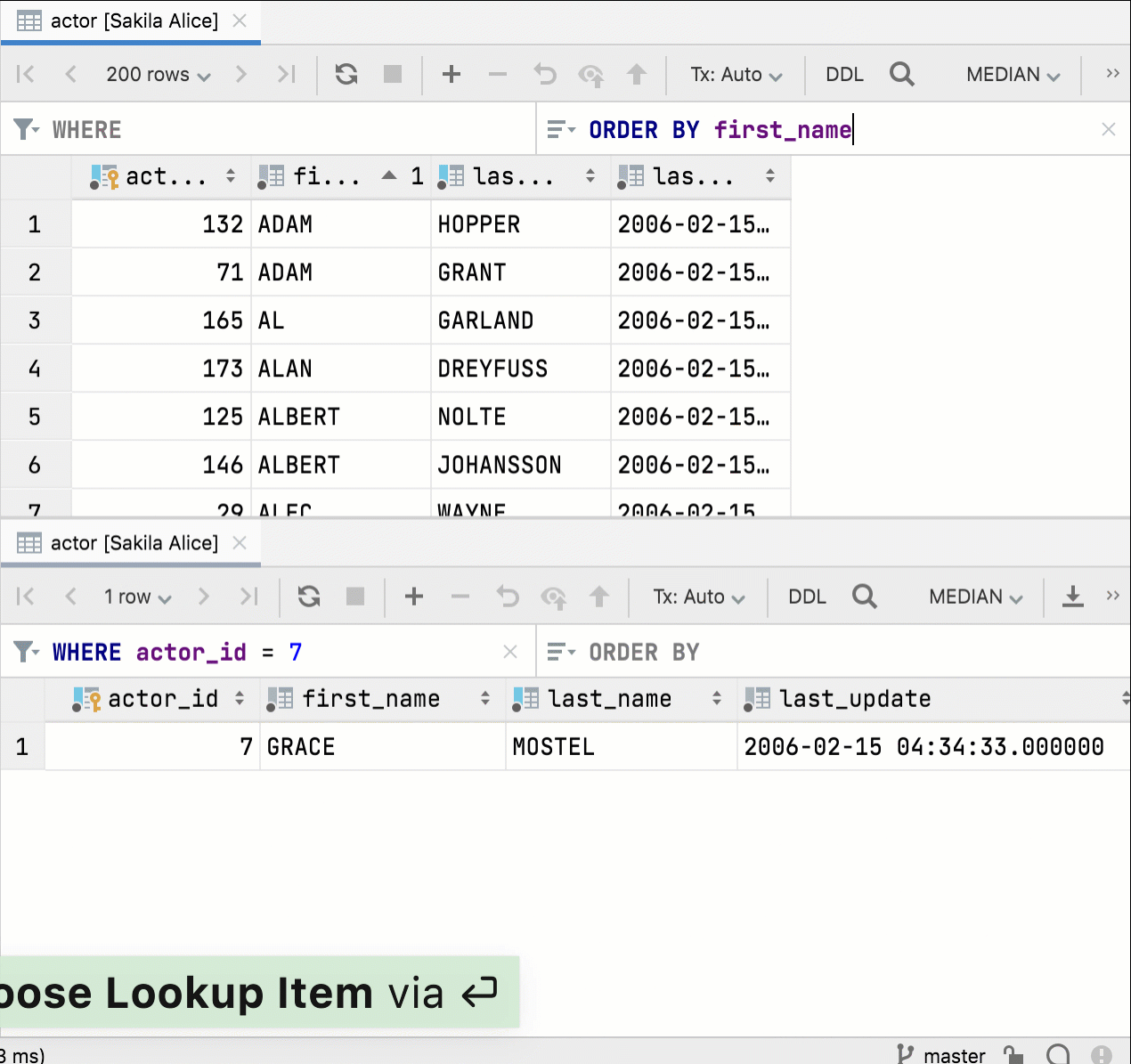
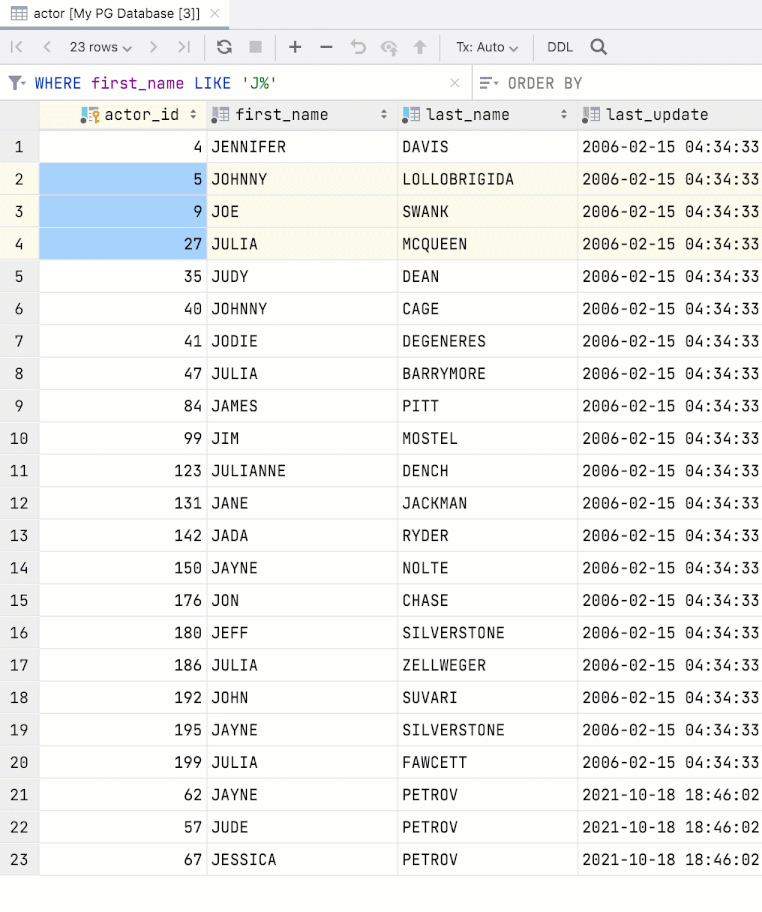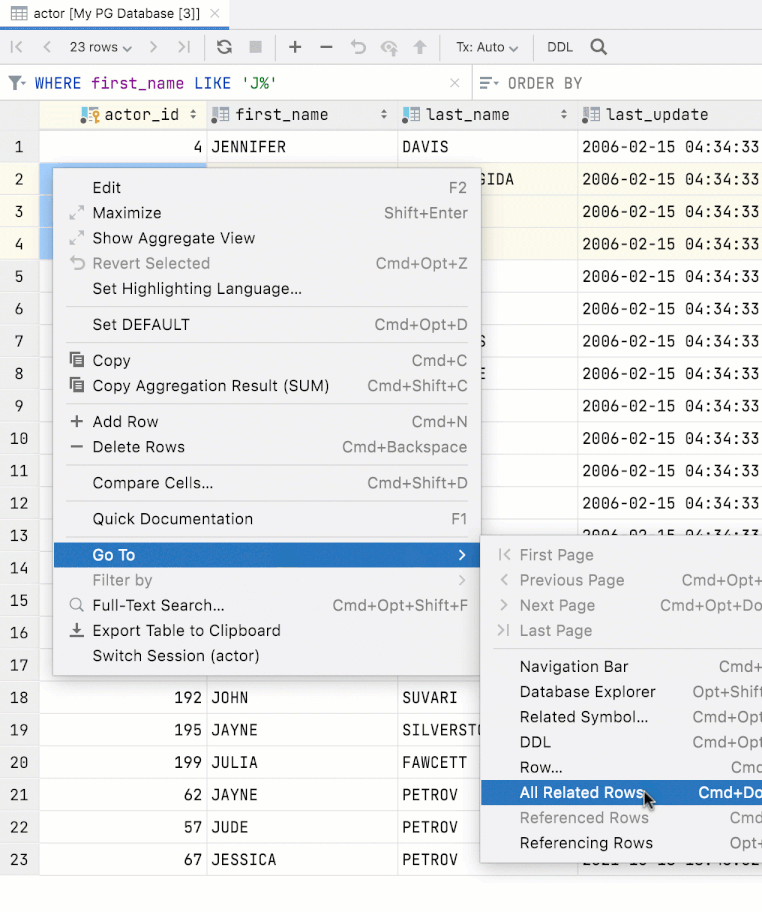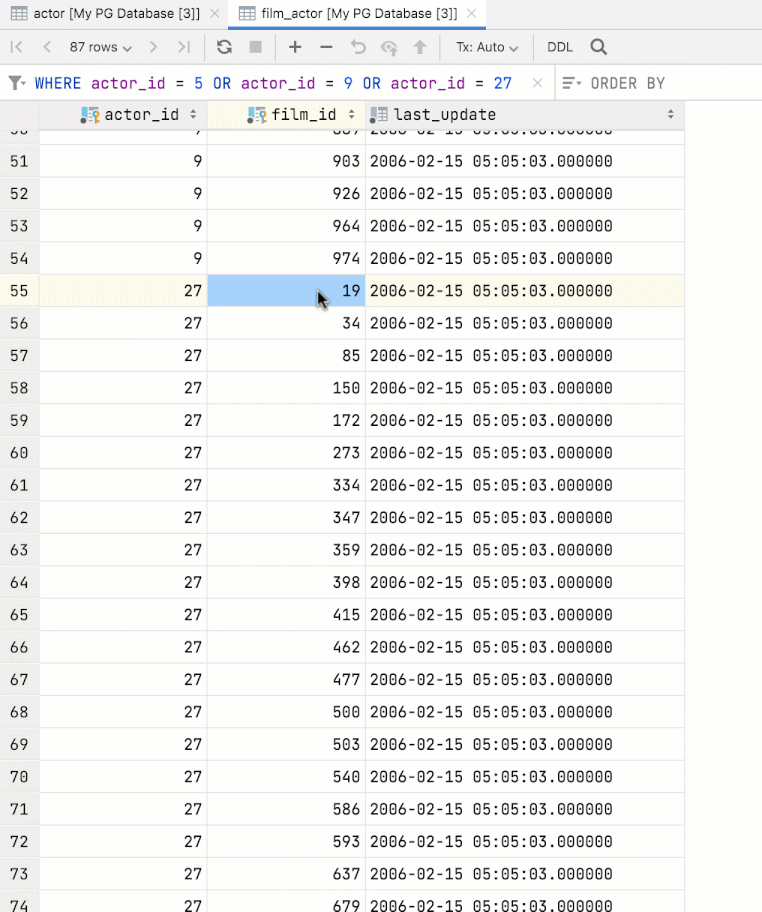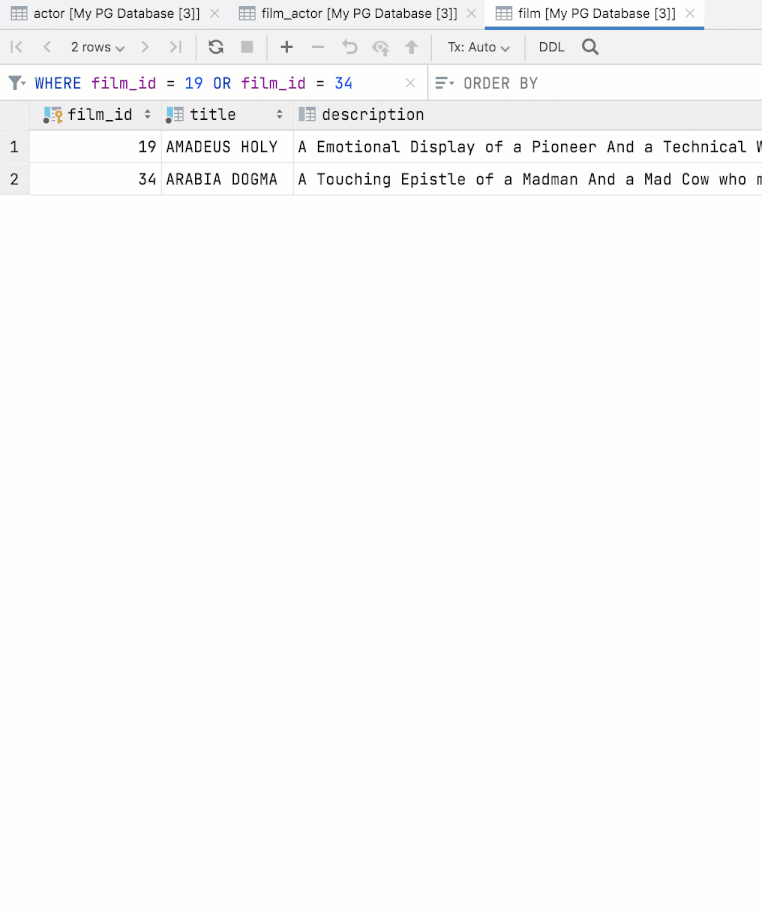
Navigation par clé étrangère basée sur plusieurs valeurs
L'éditeur de données permet à présent de sélectionner plusieurs valeurs et de naviguer dans les données associées.
Configuration du tri par défaut
Vous pouvez spécifier la méthode de tri par défaut pour les tableaux en choisissant entre ORDER BY et client-side. Si vous sélectionnez client-side, DataGrip n'effectue pas de nouvelles requêtes et ne trie que la page actuelle. Ce paramètre est disponible dans la section Database | Data views | Sorting | Sort via ORDER BY.
Mode d'affichage pour les données binaires
Les données de 16 octets s'affichent désormais au format UUID par défaut. Vous pouvez également personnaliser la façon dont les données binaires s'affichent dans la colonne de l'éditeur de données.
MongoDB : saisie semi-automatique pour filter {} et sort {}
L'autocomplétion du code est maintenant disponible lorsque vous filtrez les données dans les collections MongoDB.
Conservation de votre base de données dans le VCS
Mappage de la source de données DDL et de la source réelle
Cette version vient compléter la précédente version de l'EDI dans laquelle JetBrains a introduit la possibilité de générer une source de données DDL basée sur une source réelle. Désormais, ce workflow est totalement pris en charge. Vous pouvez :
- Générer une source de données DDL à partir d'une source réelle.
- Mapper une source de données DDL et une source réelle.
- Comparer et synchroniser ces sources dans les deux sens.
Pour rappel, une source de données DDL est une source de données virtuelle dont le schéma repose sur un ensemble de scripts SQL. Le stockage de ces fichiers dans le système de contrôle de version (VCS) est une méthode possible pour conserver votre base de données dans ce système. Les propriétés de configuration des données comportent un nouvel onglet, DDL mappings, permettant de définir quelle source de données réelle est mappée à chaque source de données DDL.
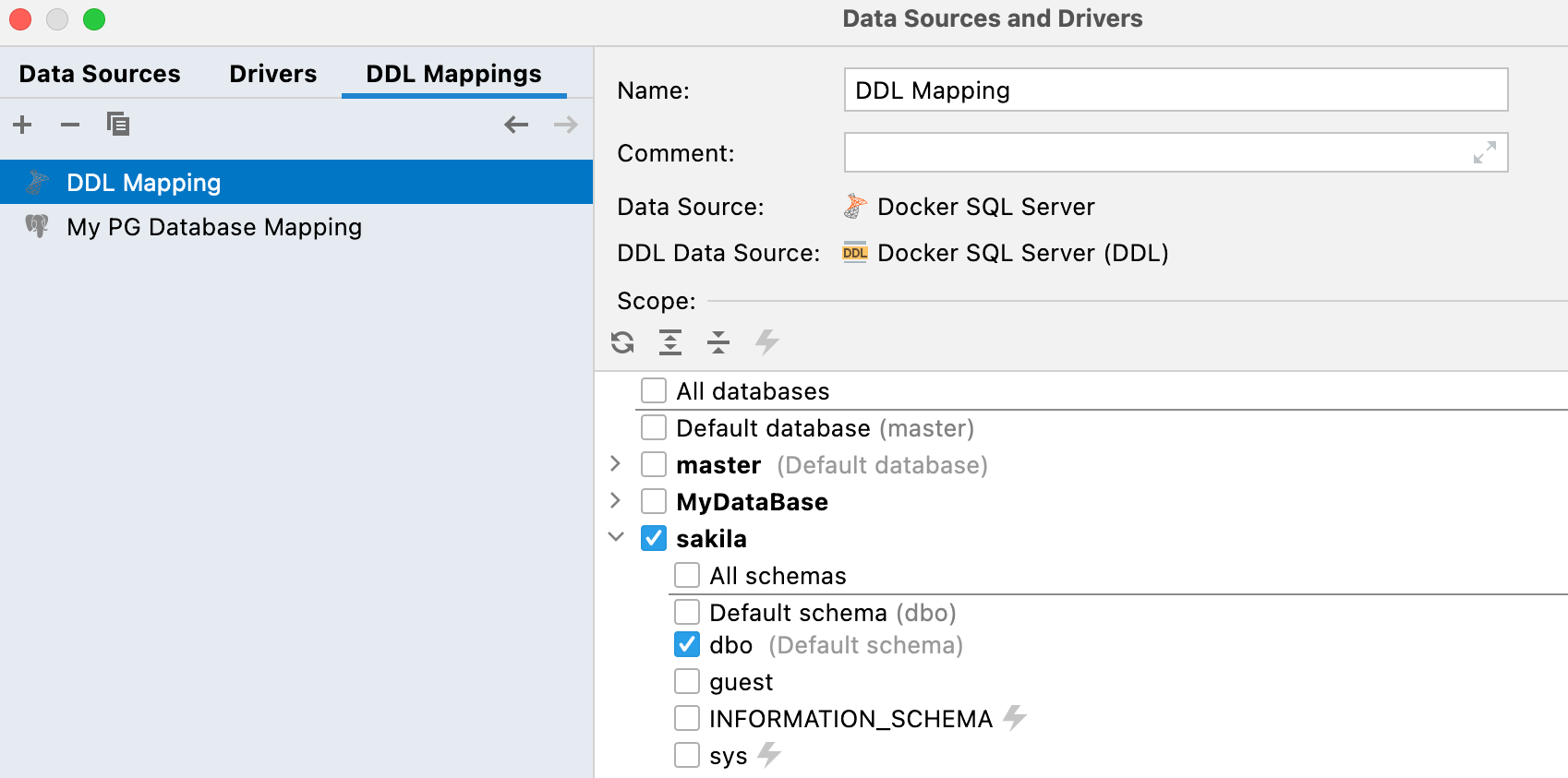
Nouvelle fenêtre de comparaison des bases de données
Pour comparer et synchroniser votre source de données DDL avec la source réelle, utilisez le menu contextuel et sélectionnez Apply from... ou Dump to... dans le sous-menu DDL
L'interface utilisateur de cette fenêtre indique clairement dans le panneau de droite les résultats que vous obtiendrez après la synchronisation.
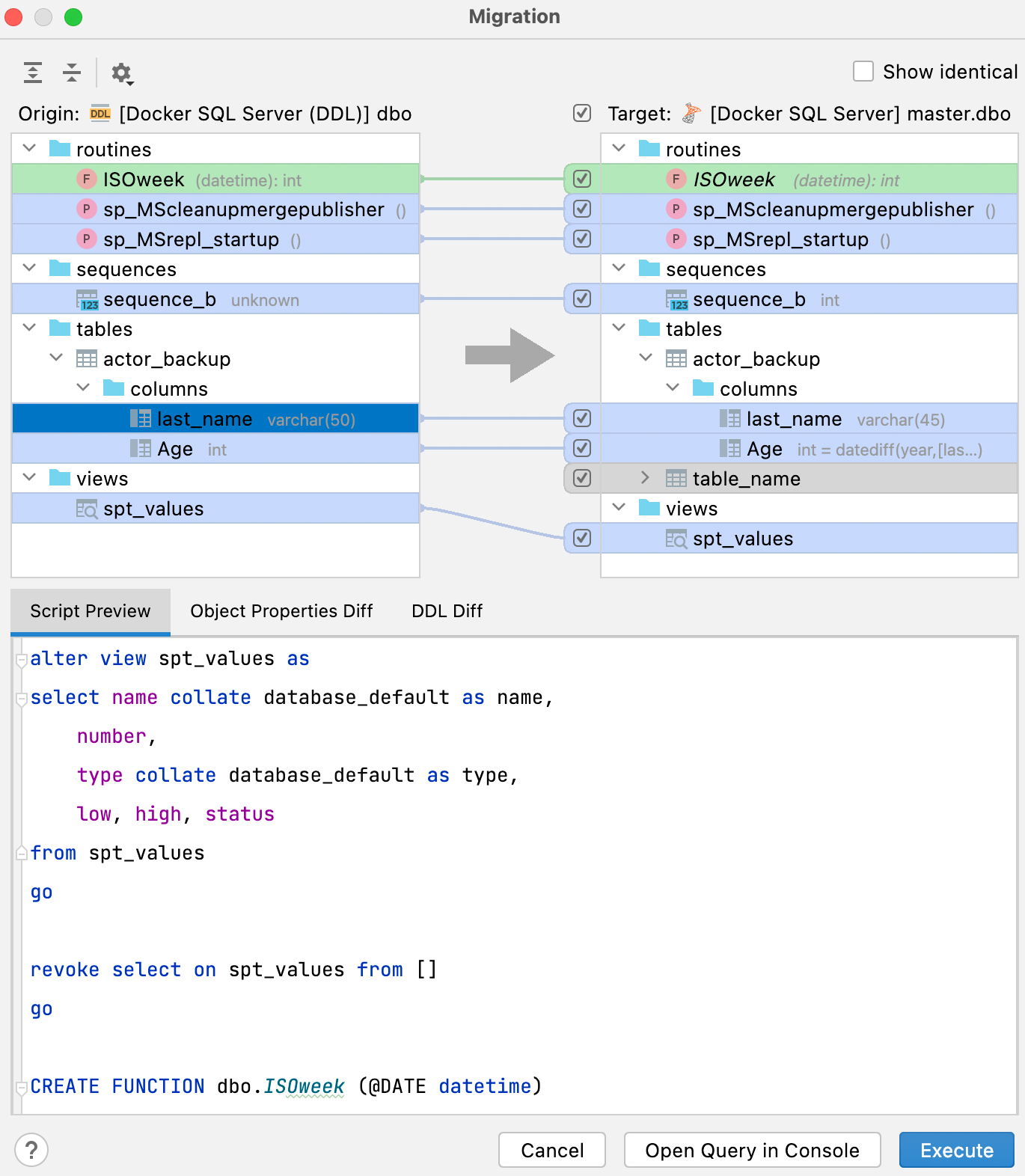
La légende du panneau droit indique la signification des couleurs pour votre résultat potentiel :
- Vert et italique : l'objet sera créé.
- Gris : l'objet sera supprimé.
- Bleu : l'objet sera modifié.
L'onglet Script preview affiche le script du résultat qui peut ensuite être ouvert dans une nouvelle console ou exécuté depuis cette boîte de dialogue. Le résultat de ce script applique les modifications pour faire de la base de données de droite (cible) une copie de la base de données de gauche (source).
Outre l'onglet Script preview, le panneau inférieur comporte deux autres onglets : Object Properties Diff et DDL Diff. Ils indiquent les différences entre les versions particulières de l'objet dans les bases de données source et cible.
Rappel : si vous souhaitez seulement comparer deux schémas ou objets, sélectionnez-les et appuyez sur Ctrl + D.
Il est également important de noter que la visionneuse Diff est en cours de développement. Dans la mesure où chaque base de données a ses propres caractéristiques, certains objets peuvent sembler différents, alors qu'ils sont en fait identiques. Cela peut être dû aux alias de type ou à l'omission des propriétés par défaut lors de la génération. Si vous rencontrez ce bug, JetBrains vous invite à le signaler dans son système de suivi.
Actions liées au fichier
Toutes les actions sur les fichiers sont également disponibles dans les éléments de source de données DDL. Par exemple, vous pouvez supprimer, copier ou valider les fichiers liés aux éléments du schéma depuis l'explorateur de base de données.
Synchronisation automatique
Si cette option est activée, votre source de données DDL sera automatiquement actualisée en fonction des modifications des fichiers correspondants. Il s'agissait déjà du comportement par défaut, mais vous avez désormais la possibilité de le désactiver.
Si vous le désactivez, les modifications des fichiers sources ne seront pas automatiquement reportées dans la source de données DDL, vous devrez cliquer sur Refresh pour les appliquer.
Configuration des schémas et des bases de données par défaut
Le panneau Default schemas/databases permet de définir les noms de votre base de données et de vos schémas qui s'afficheront ensuite dans la source de données DDL. Les scripts DDL ne contiennent généralement pas de noms, et dans de tels cas, des noms factices sont utilisés par défaut pour les bases de données et les schémas.
Connectivité
Signalement des espaces accidentels
Si une valeur, hormis User ou Password, comporte des espaces au début ou à la fin, DataGrip vous le signale lorsque vous cliquez sur Test Connection.
LocalDB en tant que source de données dédiée (SQL Server)
SQL Server LocalDB dispose de son propre pilote dédié dans la liste de pilotes. Cela signifie que le type de sa source de données est différent et qu'il doit être utilisé pour LocalDB. Cela présente les avantages suivants :
- La connexion LocalDB est plus facile à examiner.
- Vous ne devez configurer le chemin du fichier exécutable qu'une seule fois, dans les options du pilote, puis il s'appliquera à toutes les sources de données.
Authentification Kerberos (Oracle et SQL Server)
Il est désormais possible d'utiliser l'authentification Kerberos dans Oracle et SQL Server. Vous devez tout d'abord obtenir un ticket TGT (ticket-granting ticket) pour le principal en exécutant la commande kinit, puis DataGrip l'utilisera lorsque vous choisissez l'option Kerberos.
Activation de DBMS_OUTPUT (Oracle, IBM Db2)
Une nouvelle option de l'onglet Options vous permet d'activer DBMS_OUTPUT par défaut pour les nouvelles sessions.
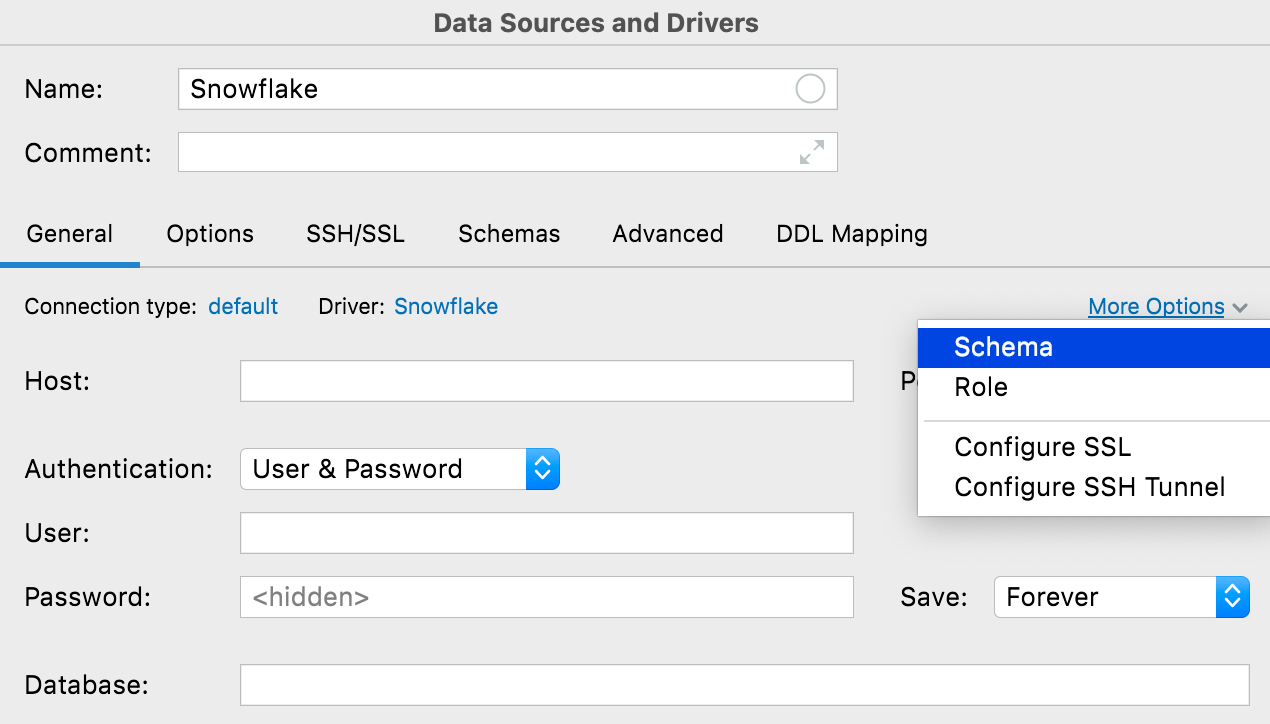
Bouton More options
JetBrains a ajouté le bouton More Options pour vous permettre de mieux gérer les configurations inhabituelles lors d'une connexion. Les options actuellement disponibles permettent d'ajouter les champs Schema et Role pour les connexions Snowflake et deux éléments de menu pour configurer SSH et SSL, afin d'en faciliter la découverte.
Fonctionnalités avancées
L'onglet Advanced comporte désormais une liste Expert Options. Outre l'option d'activation de l'introspecteur JDBC (il est fortement conseillé de contacter l'équipe d'assistance JetBrains avant d'utiliser cette option), les options suivantes, propres à la base de données, sont disponibles :
- Oracle : Disable incremental introspection, Fetch LONG values et Introspect server objects
- SQL Server : Disable incremental introspection
- PostgreSQL (ou similaire) : Disable incremental introspection et Do not use xmin in queries to pgdatabase
- SQLite : Register REGEXP function
- MYSQL : Use SHOW/CREATE for source code
- ClickHouse : Automatically assign sessionid
Introspection
Niveaux d'introspection (Oracle)
Les utilisateurs d'Oracle ont rencontré un problème au niveau de l'introspection de DataGrip. En effet, cette procédure prenait trop de temps en présence de nombreuses bases de données et de nombreux schémas. L'introspection désigne le processus d'obtention des métadonnées de la base de données, telles que les noms d'objet et le code source. DataGrip l'utilise pour fournir une assistance au codage, une navigation et des recherches rapides.
L'accès aux catalogues système Oracle est relativement lent et l'introspection l'était encore plus si l'utilisateur ne disposait pas de droits d'administration. JetBrains a fait de son mieux pour optimiser les requêtes d'obtention des métadonnées, mais tout a des limites.
L'éditeur de logiciels pour développeurs a constaté que pour la plupart des tâches quotidiennes, y compris pour assurer une assistance efficace du codage, il n'est pas nécessaire de charger les sources des objets. Dans la plupart des cas, connaître les noms d'objets de la base de données est suffisant pour assurer la saisie semi-automatique du code et la navigation. Par conséquent, JetBrains a introduit trois niveaux d'introspection pour les bases de données Oracle :
- Niveau 1 : noms de tous les objets pris en charge et leurs signatures, à l'exception des noms de colonnes d'index et des variables de paquets privés ;
- Niveau 2 : tout, à l'exception du code source ;
- Niveau 3 : tout.
L'introspection est la plus rapide au niveau 1 et la plus lente au niveau 3. Choisissez le niveau d'introspection voulu dans le menu contextuel :
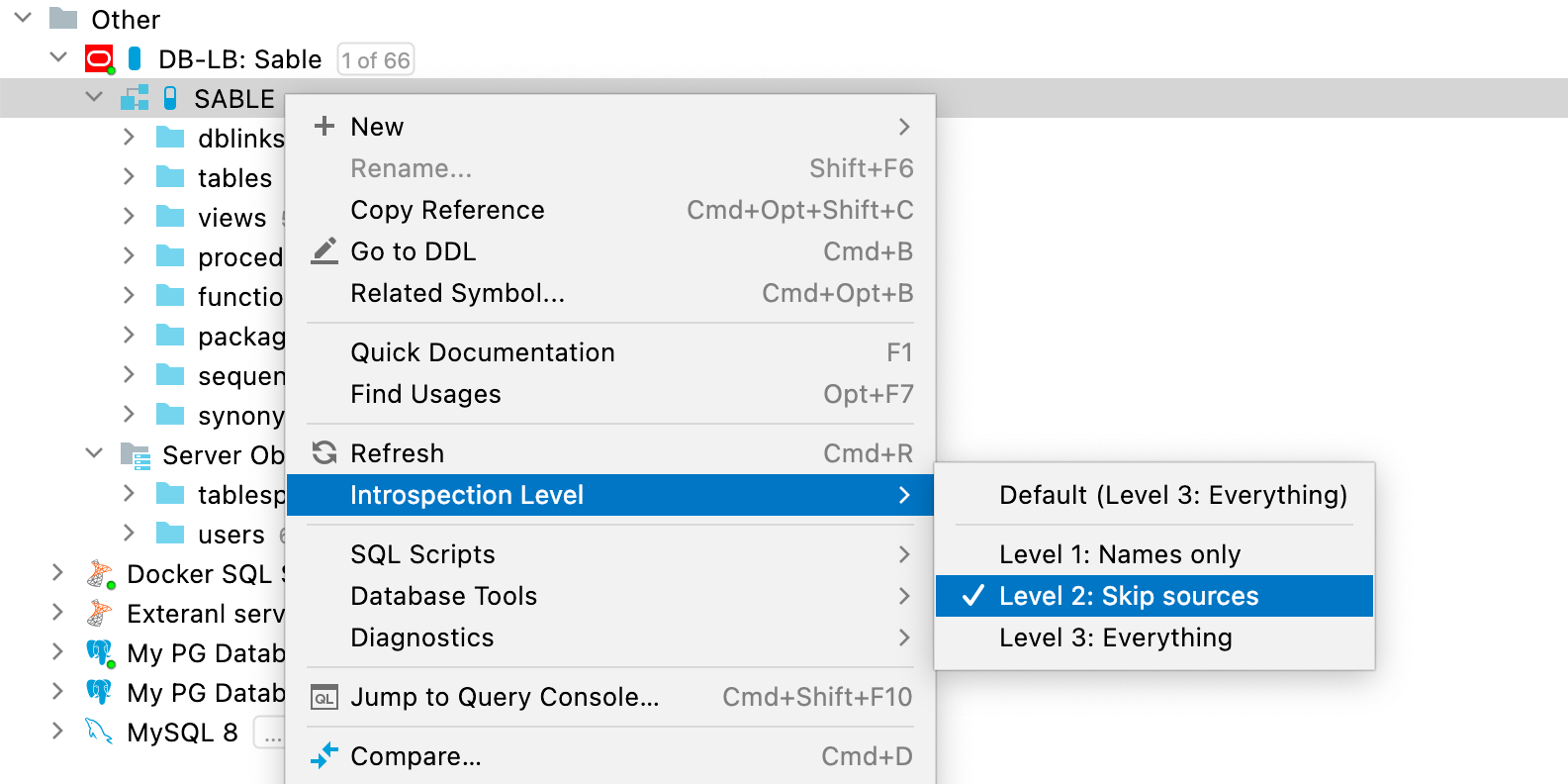
Le niveau d'introspection peut s'appliquer à un schéma ou l'intégralité de la base de données. Les schémas héritent leur niveau d'introspection de la base de données, mais ils peuvent également être configurés de façon indépendante.
Le niveau d'introspection est représenté par les icônes en forme de pilule, près de l'icône de source de données. Plus la pilule est remplie, plus le niveau d'introspection est élevé. Une icône bleue signifie que le niveau d'introspection est configuré directement, tandis qu'une icône grise signifie qu'il est hérité.

Mappage des serveurs liés et des liens de base de données aux sources de données (SQL Server, Oracle)
Vous pouvez mapper votre serveur lié dans SQL Server ou votre lien de base de données dans Oracle avec une source de données valide. Et lorsque des objets externes sont mappés à la source de données, la saisie automatique du code et la résolution fonctionnent pour les requêtes utilisant ces objets externes.
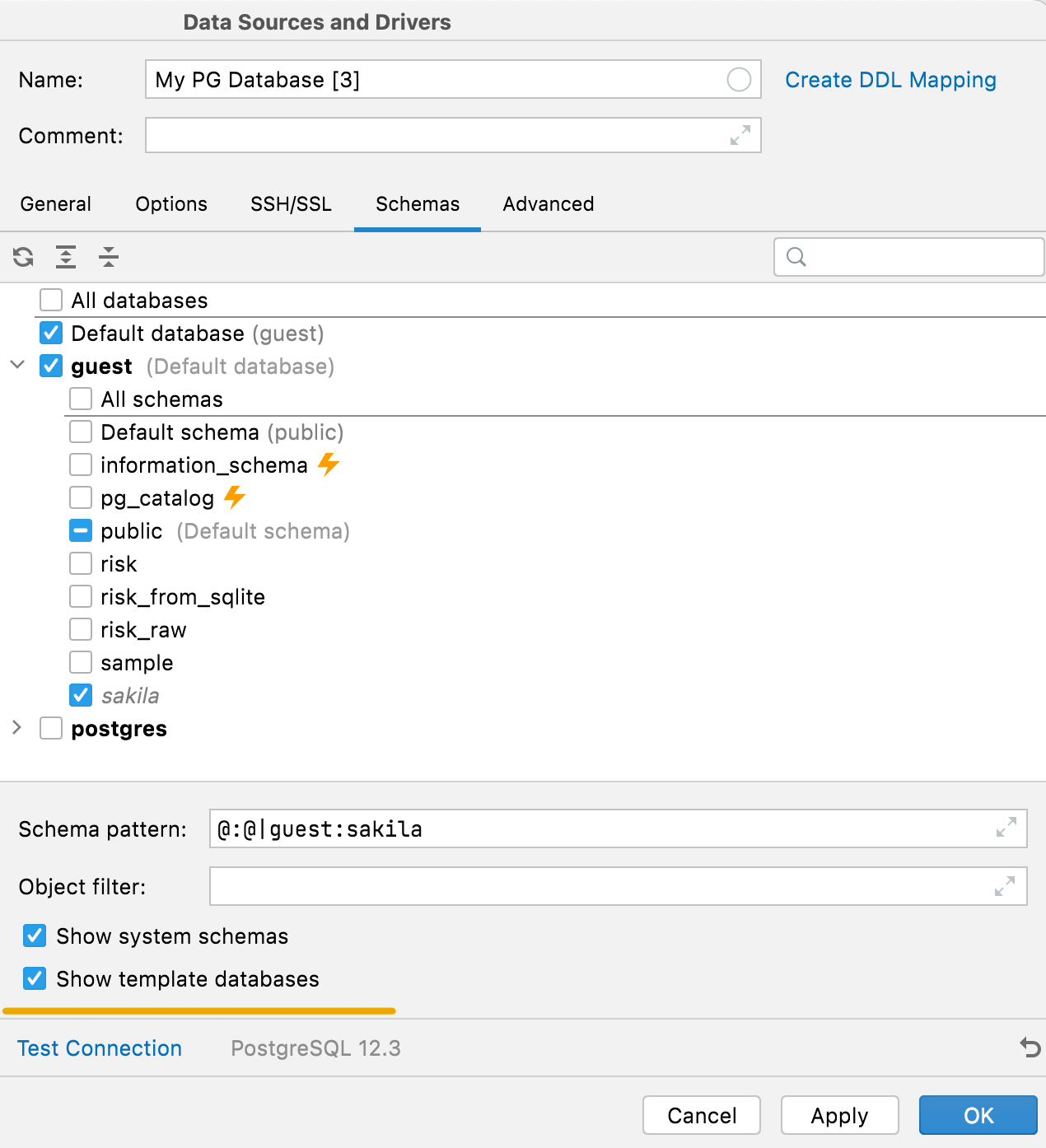
Masquage des schémas système et des bases de données de modèles (PostgreSQL)
Les schémas système internes (tels que pg_toast ou pg_temp) et les bases de données de modèles étaient auparavant masqués dans la liste de schémas. Il est maintenant possible de les afficher en utilisant les options correspondantes dans l'onglet Schemas.
Prise en charge de flux (Snowflake)
Désormais, les flux s'affichent dans la vue base de données en complément des tables et des vues.
Tables distribuées (ClickHouse)
Les tables distribuées sont désormais placées sous un nud dédié, dans l'explorateur de bases de données.
Console de requête
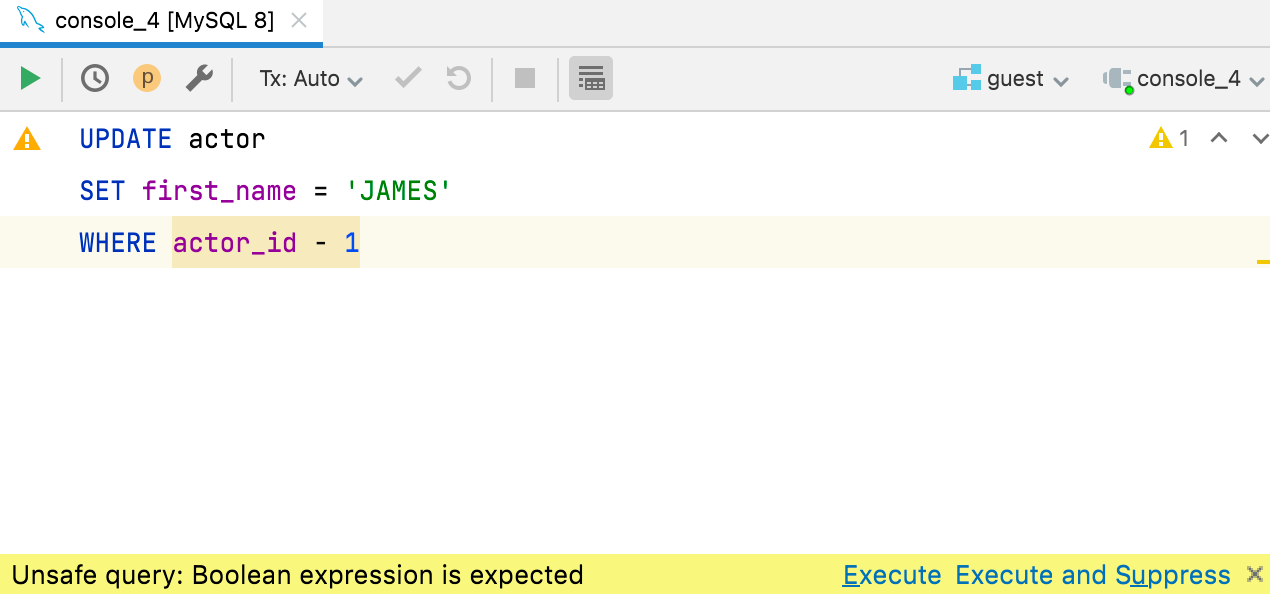
Vérification des expressions booléennes
Un utilisateur a tweeté la situation malencontreuse suivante : il a exécuté la requête UPDATE sur une base de données de production avec la condition WHERE id - 3727 (au lieu de =), ce qui a entraîné la mise à jour de millions d'enregistrements. Tout le monde était surpris que MySQL permette une telle situation, mais c'est arrivé. Pour éviter ce genre de situations à l'avenir, l'équipe DataGrip a ajouté une nouvelle inspection pour la vérification des expressions booléennes dans les clauses WHERE et HAVING.
Si l'expression ne semble pas être explicitement booléenne, DataGrip la surligne en jaune et vous avertit avant son exécution. Cela fonctionne pour ClickHouse, Couchbase, Db2, H2, Hive/Spark, MySQL/MariaDB, Redshift, SQLite et Vertica. Dans toutes les autres bases de données, cela est signalé comme une erreur.
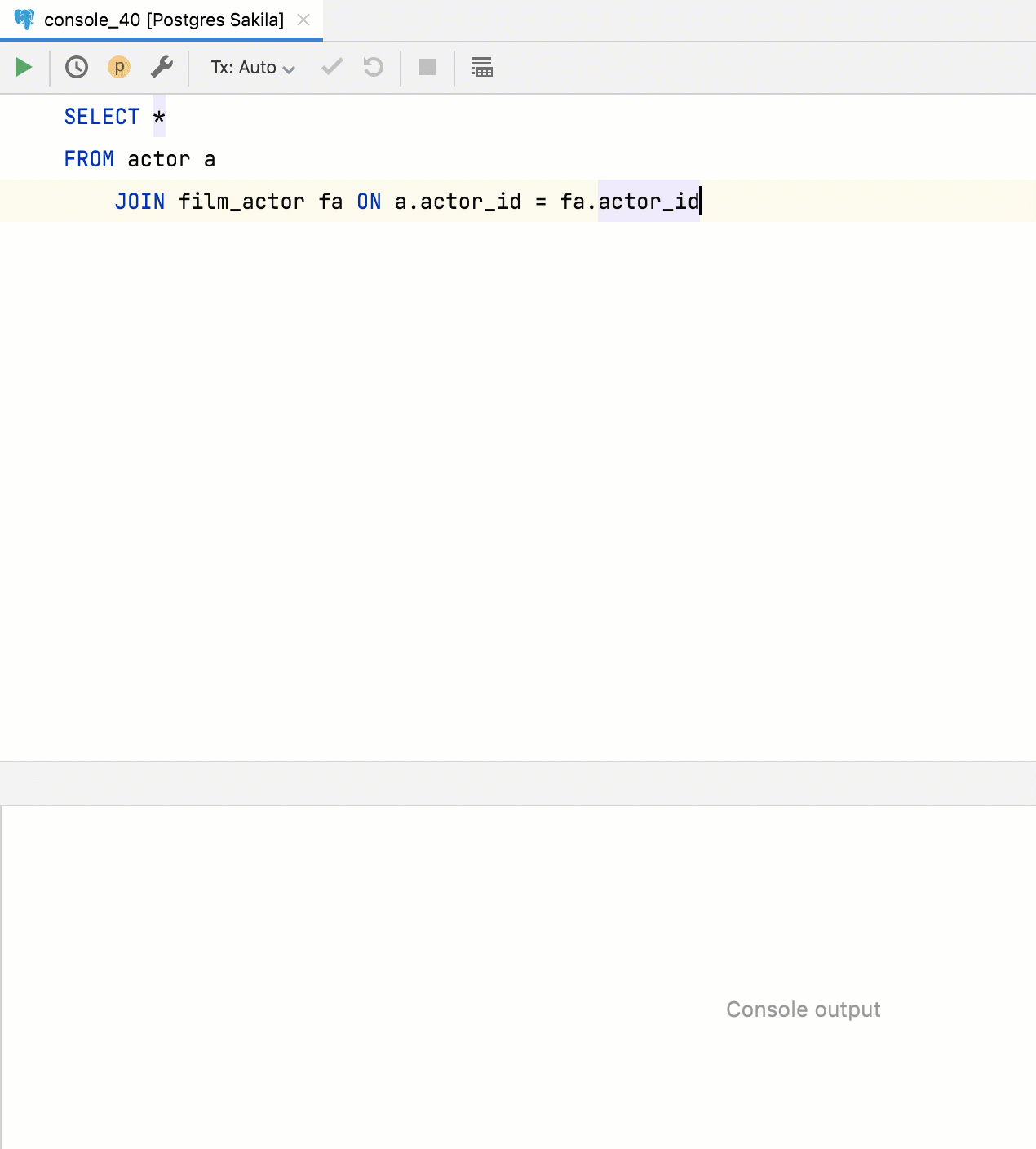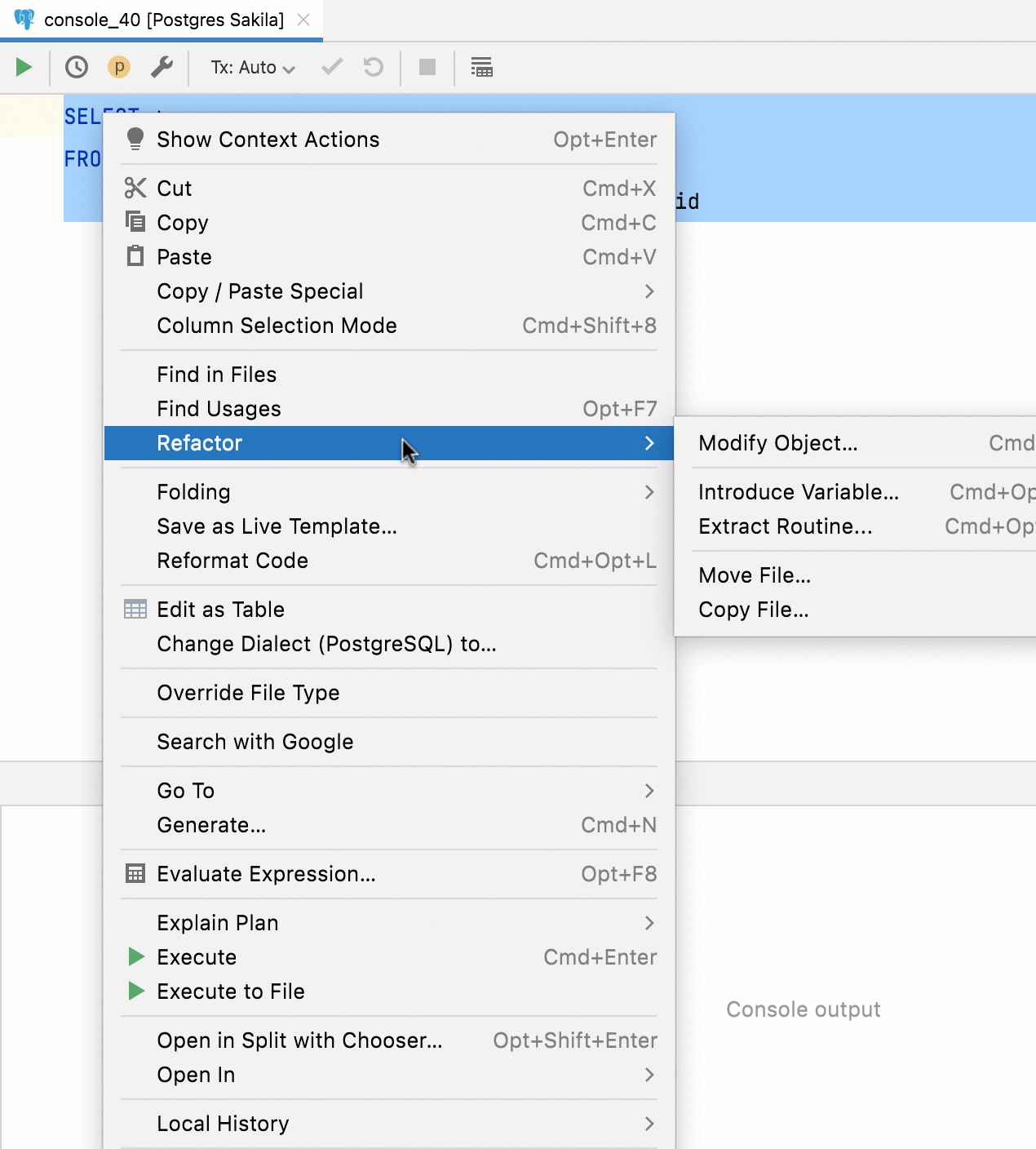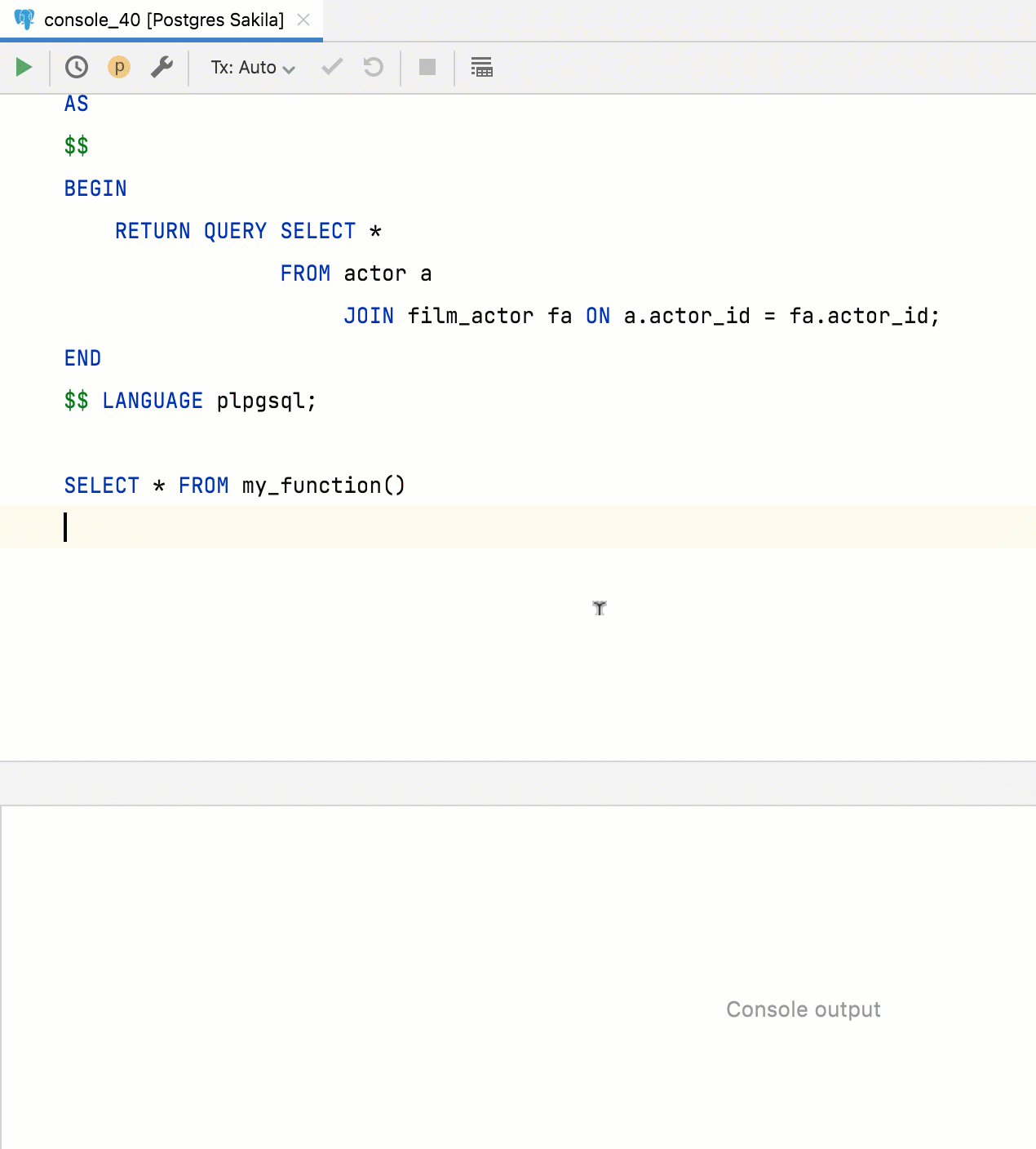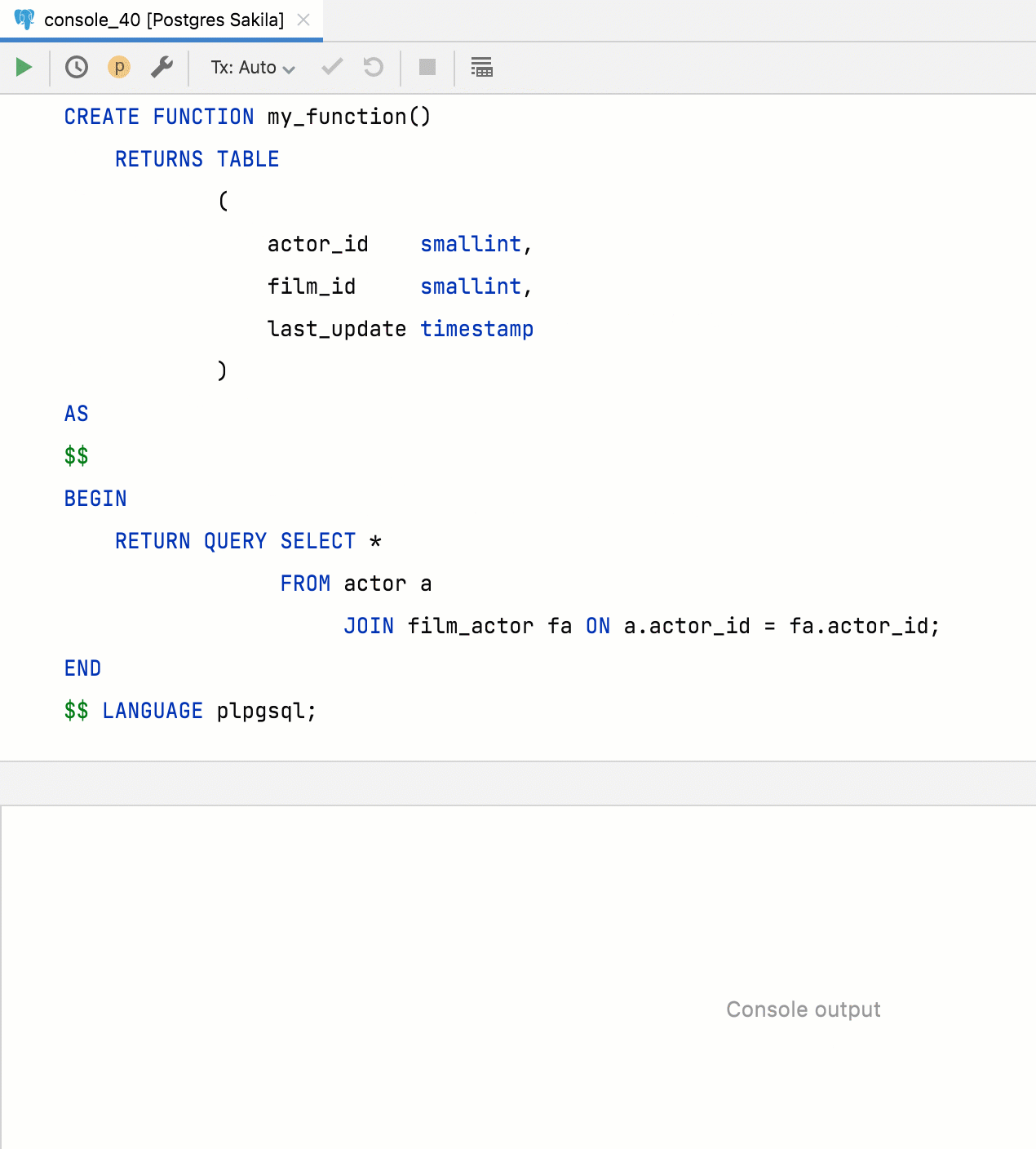
Extraction de fonction pour les requêtes
Désormais, les requêtes peuvent être extraites en tant que fonction de table. Pour ce faire, sélectionnez la requête, appelez le menu Refactor et utilisez Extract Routine.
Conseil d'incrustation de cardinalité JOIN
Le nouveau conseil d'incrustation vous informe de la cardinalité d'une clause JOIN. Trois options sont possibles : un-à-un, un à plusieurs et plusieurs à plusieurs. Si vous souhaitez le désactiver, vous pouvez modifier ce paramètre dans Preferences | Editor | Inlay Hints | Join cardinality.
Saisie semi-automatique du code pour les noms de base de données (MongoDB)
Les noms de base de données sont saisis automatiquement lorsque vous utilisez getSiblingDB et les noms de collection sont complétés si vous utilisez getCollection.
En outre, les noms de champs sont automatiquement complétés et résolus s'ils proviennent d'une collection définie avec getCollection.
Fenêtre d'outils Services
Horodatages masqués par défaut dans les résultats
Suite à la demande des utilisateurs, les horodatages ne s'affichent plus par défaut dans les résultats des requêtes. Si vous souhaitez rétablir le comportement précédent, modifiez ce paramètre dans Database | General | Show timestamp for query output.
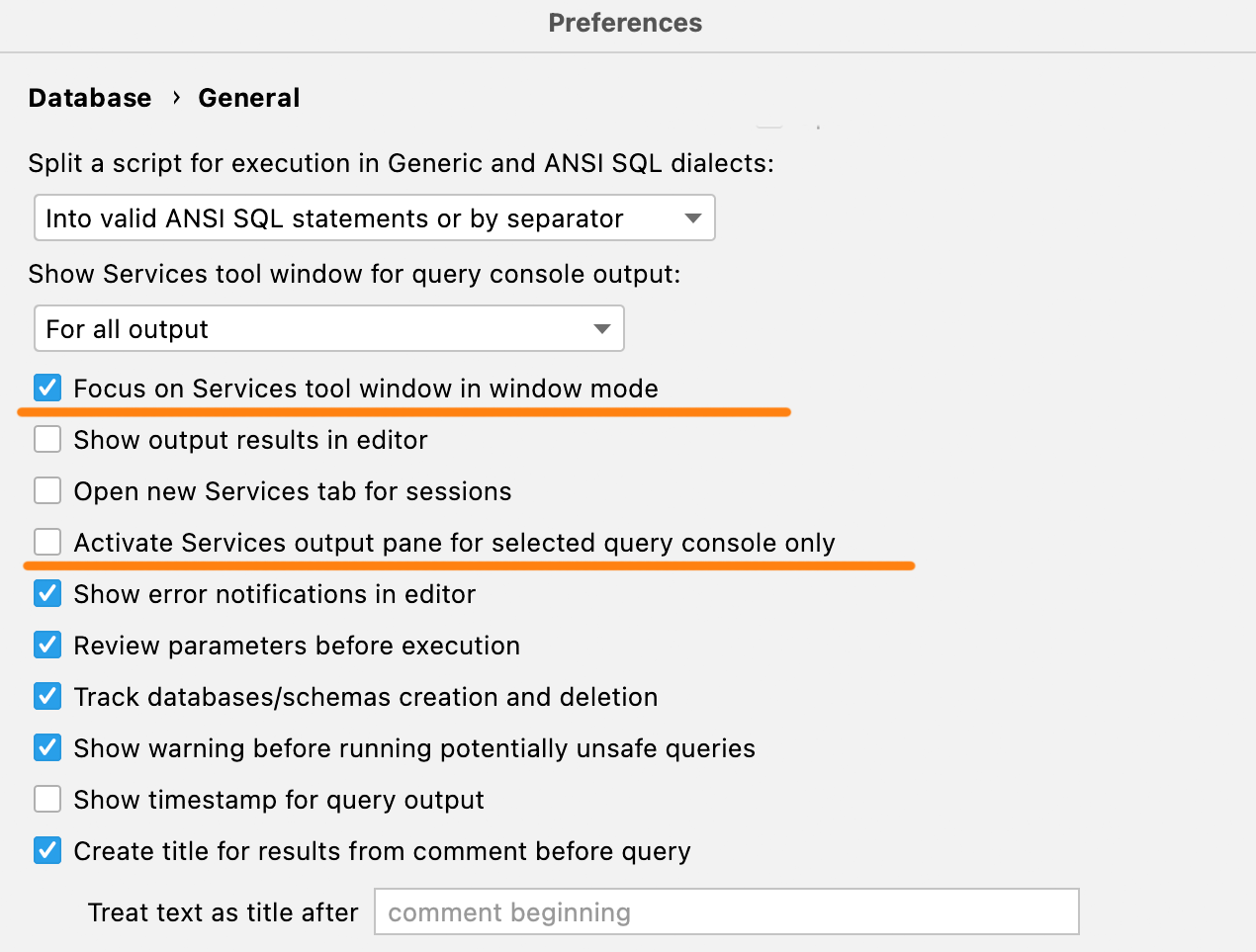
Nouveaux paramètres d'activation
Si vous utilisez la fenêtre d'outils Services en mode fenêtre, elle est masquée par défaut derrière l'EDI. Ce nouveau paramètre vous permet de lui redonner le focus à chaque fois que vous exécutez une requête, de sorte qu'elle s'affiche dès que la requête est terminée.
D'autre part, si vous ne souhaitez plus que l'onglet correspondant dans la fenêtre d'outil Services s'active lorsque vous finissez une requête longue dans une autre console, cochez la case Activate Services output pane for selected query console only.
Importation/Exportation
Nouvelle interface d'importation des données
Lors de l'importation de fichiers .csv ou de la copie de tables/jeux de résultats, vous observerez les améliorations suivantes :
- Vous pouvez choisir une table existante ou en créer une.
- Vous pouvez changer le schéma cible dans la boîte de dialogue d'importation. La boîte de dialogue dédiée de la cible ne s'affiche pas si vous copiez une table ou un jeu de résultats.
- La cible est enregistrée en tant que valeur par défaut par schéma. Par conséquent, si vous réalisez constamment des copies d'un schéma à un autre, il n'est plus nécessaire de choisir le schéma cible à chaque fois.
Détection automatique First row is header
Désormais, lorsque vous ouvrez ou importez un fichier CSV, DataGrip détecte automatiquement que la première ligne est l'en-tête et contient les noms des colonnes.
Types de colonne automatiques dans les fichiers CSV
DataGrip peut désormais détecter les types de colonne dans les fichiers CSV. Le principal avantage de cette option est que vous pouvez trier les données par valeurs numériques. Auparavant, elles étaient traitées comme du texte et le tri n'était pas intuitif.
Divers
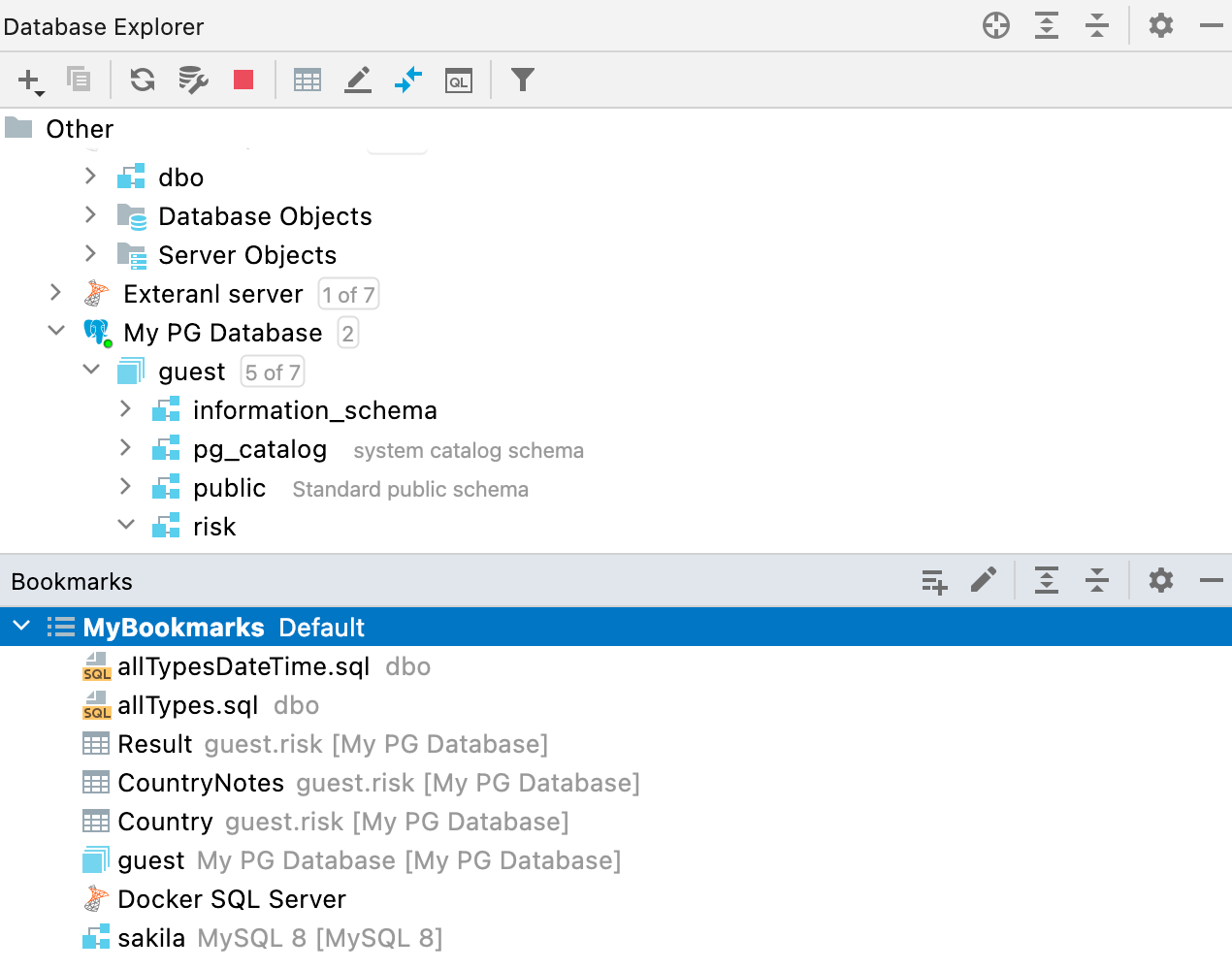
Nouvelle fenêtre d'outils Bookmarks
Auparavant, DataGrip avait deux instances très similaires : Favorites et Bookmarks. La différence entre les deux prêtait parfois à confusion, JetBrains a donc décidé de n'en garder qu'une : Bookmarks. L'éditeur de logiciels pour développeurs a retravaillé le workflow de cette fonctionnalité et créé une nouvelle fenêtre d'outils dédiée.
Désormais, tous les objets ou fichiers que vous marquez comme importants (avec le raccourci F3 sous macOS ou F11 sous Windows/Linux) apparaîtront dans la nouvelle fenêtre d'outils Bookmarks.
 Télécharger DataGrip 2021.3
Télécharger DataGrip 2021.3
Vous avez lu gratuitement 6 449 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.