

 JetBrains ouvre le programme d'accès anticipé (EAP) à DataGrip 2021.3
JetBrains ouvre le programme d'accès anticipé (EAP) à DataGrip 2021.3la troisième mise à jour majeure de l'année de son EDI pour les développeurs SQL
JetBrains ouvre le programme d'accès anticipé (EAP) à DataGrip 2021.3, la troisième mise à jour majeure de l'année de son EDI de base de données conçu pour répondre aux besoins spécifiques des développeurs SQL professionnels. Elle apporte de nombreuses améliorations dans divers domaines : éditeur de données, bases de données dans le système de contrôle de version, connectivité, explorateur de données, console de requête, importation et exportation, etc. Nous présentons dans les suites ces nouveautés de manière détaillée.
Editeur de données
Agrégats
JetBrains a ajouté la possibilité d'afficher une vue Agrégat pour une plage de cellules. C'est une fonctionnalité très attendue qui vous aidera à gérer vos données et qui vous évitera d'avoir à écrire des requêtes supplémentaires. Cela rapproche l'éditeur de données d'Excel et des feuilles de calcul Google. Sélectionnez la plage de cellules pour laquelle vous souhaitez afficher la vue, puis cliquez avec le bouton droit et sélectionnez Show Aggregate View.
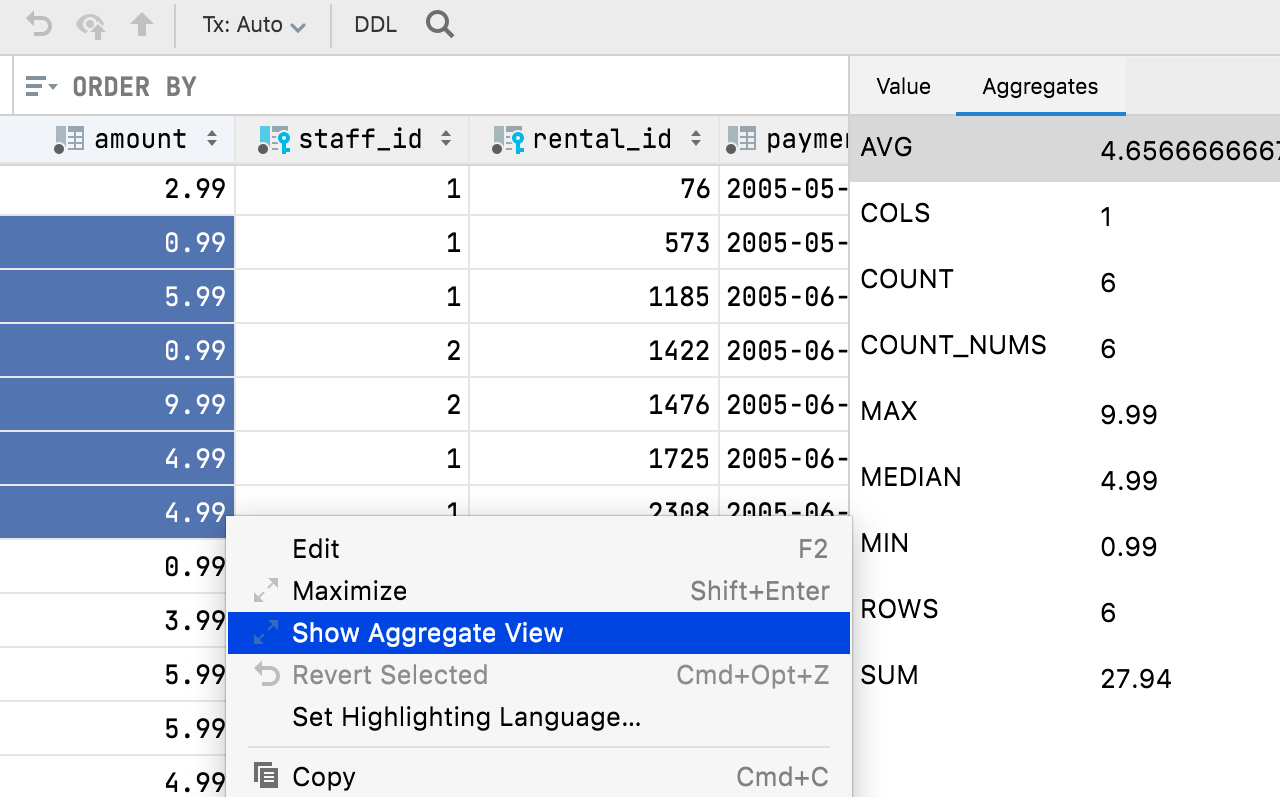
Des points à noter en ce qui concerne la vue Agrégat :
- Elle partage le panneau avec la vue Valeur : vous y avez maintenant deux onglets. Ce panneau peut être déplacé en bas de l'éditeur de données.
- Vous pouvez utiliser l'icône d'engrenage pour afficher ou masquer n'importe quel agrégat à partir de cette vue.
- Comme les extracteurs, les agrégats sont des scripts. Vous pouvez créer et partager les vôtres en plus des neuf scripts disponibles par défaut.
- De plus, les scripts d'agrégats et extracteurs sont interchangeables. Si vous avez déjà utilisé un extracteur pour obtenir une seule valeur, vous pouvez maintenant la copier dans le dossier Aggregates et l'utiliser pour les agrégats.
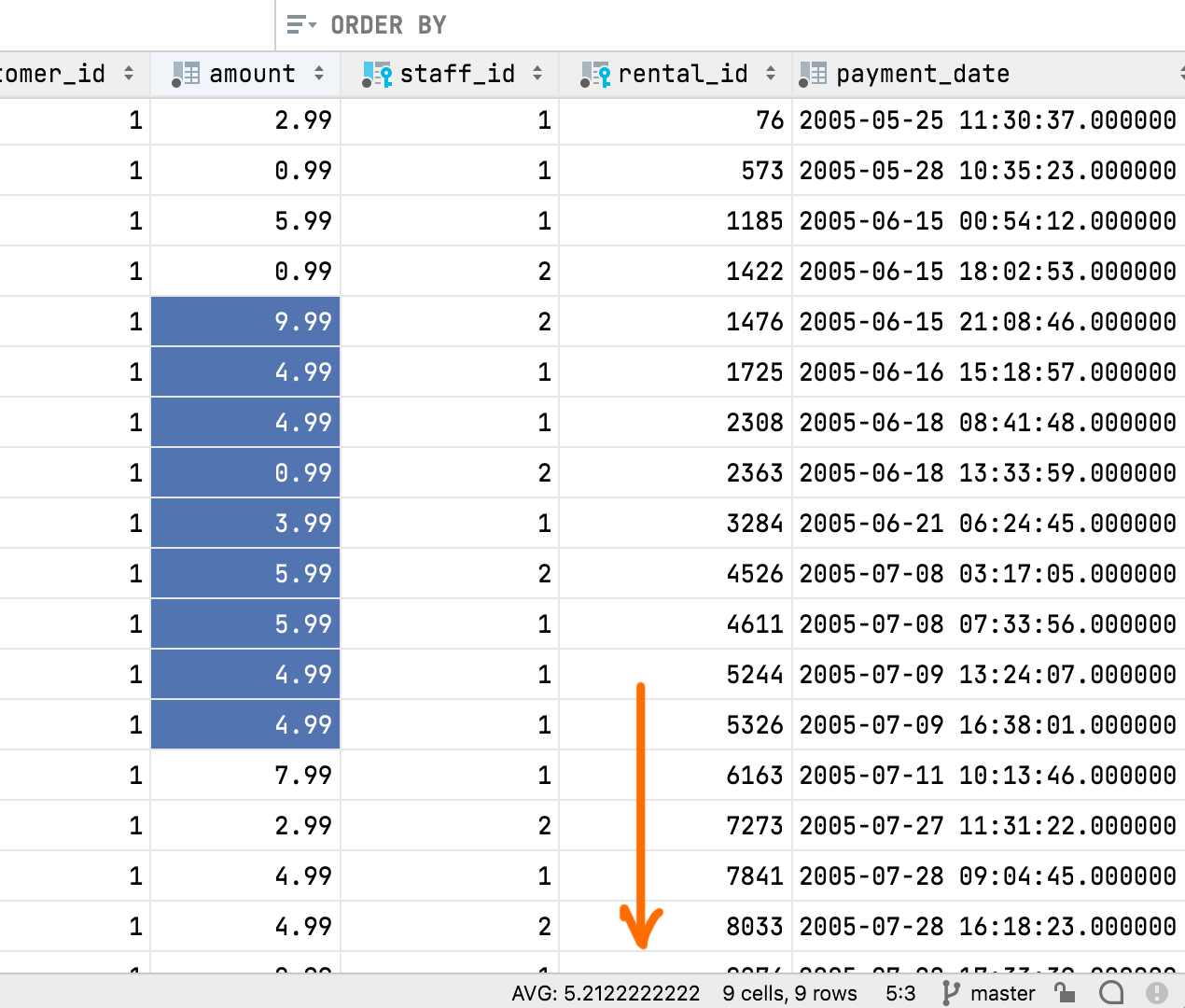
Une valeur agrégée est affichée dans la barre d'état et vous pouvez choisir la valeur (le type d'agrégat) que vous voulez qu'elle soit.
Fractions indépendantes de l'éditeur
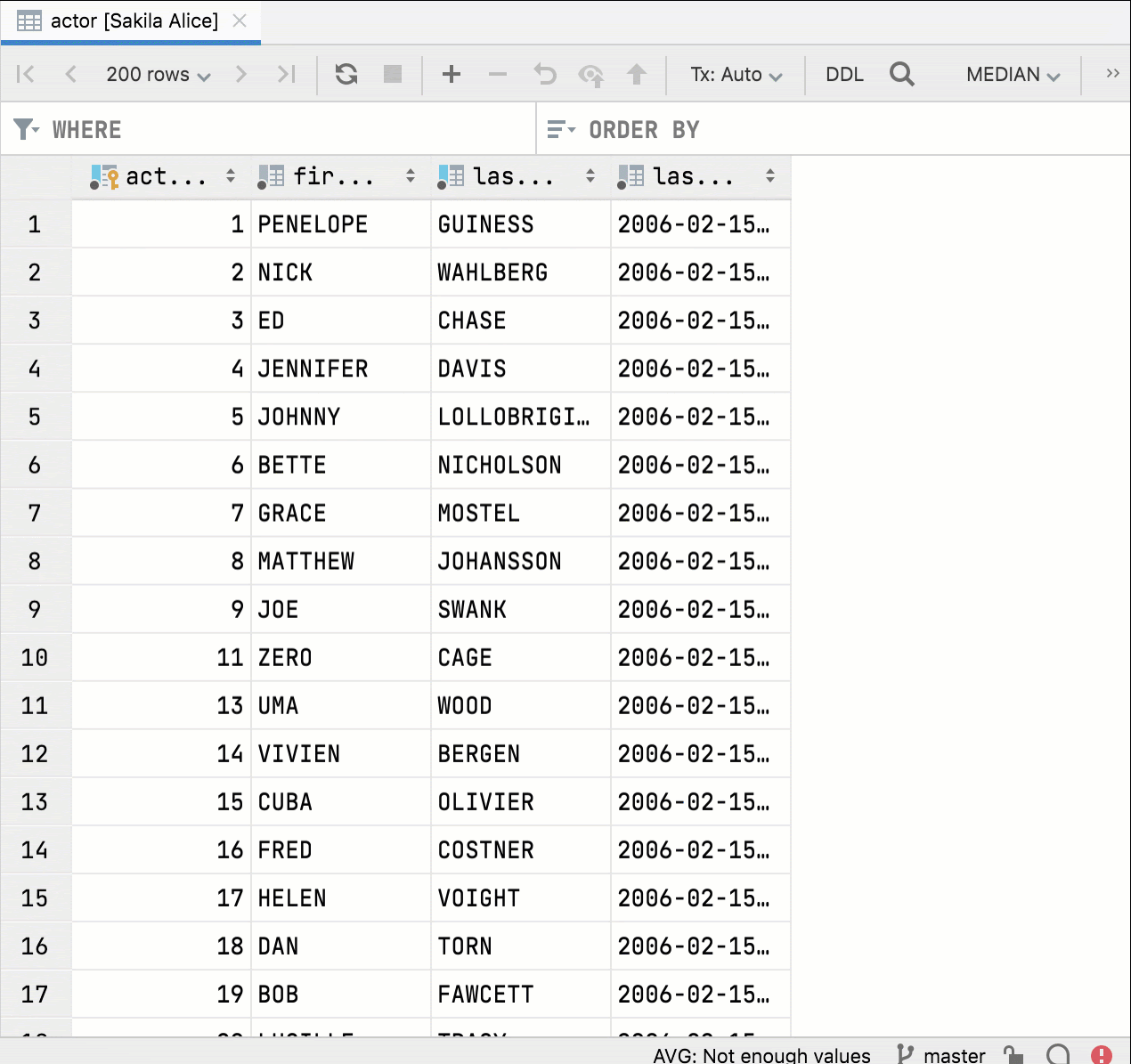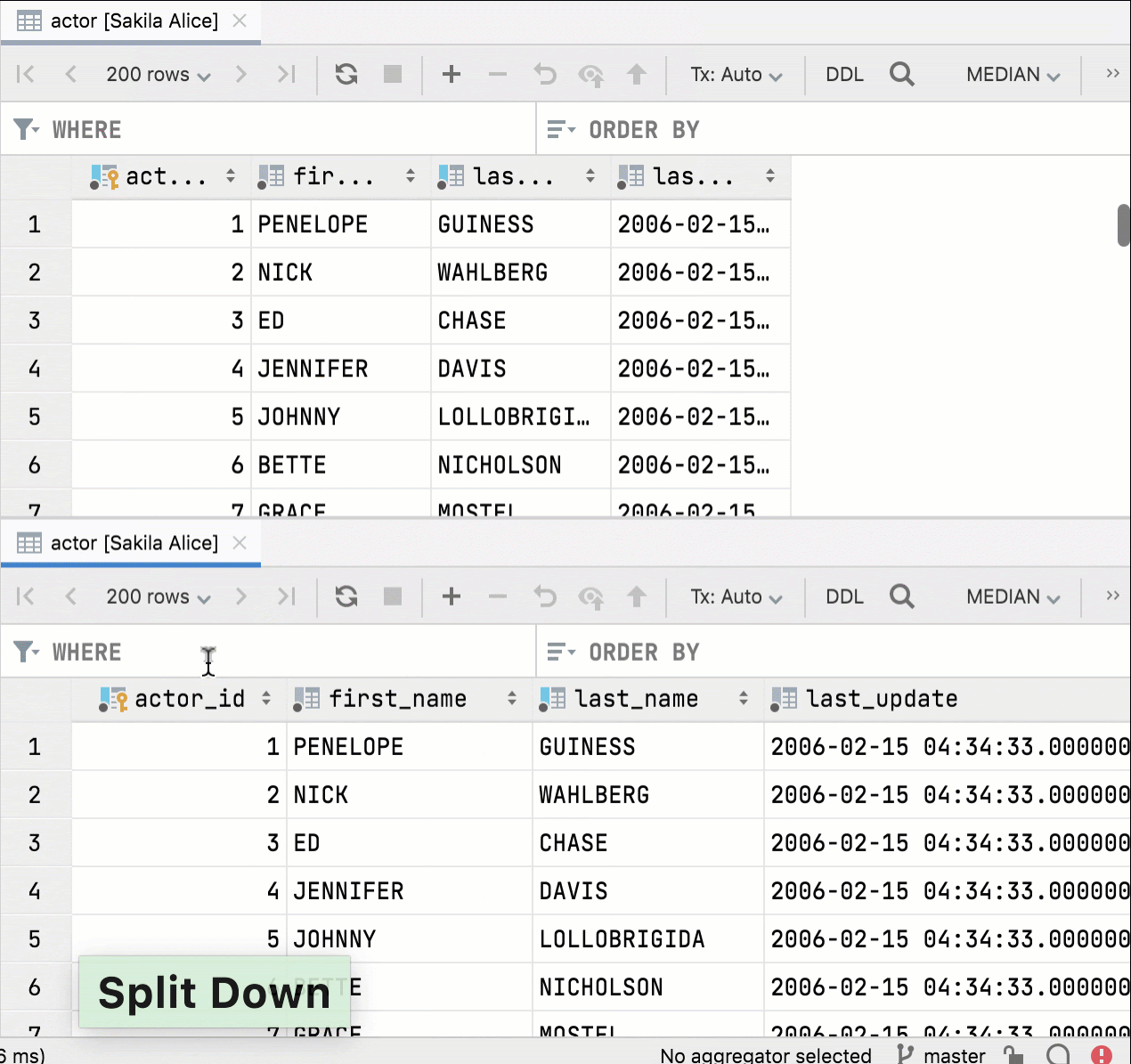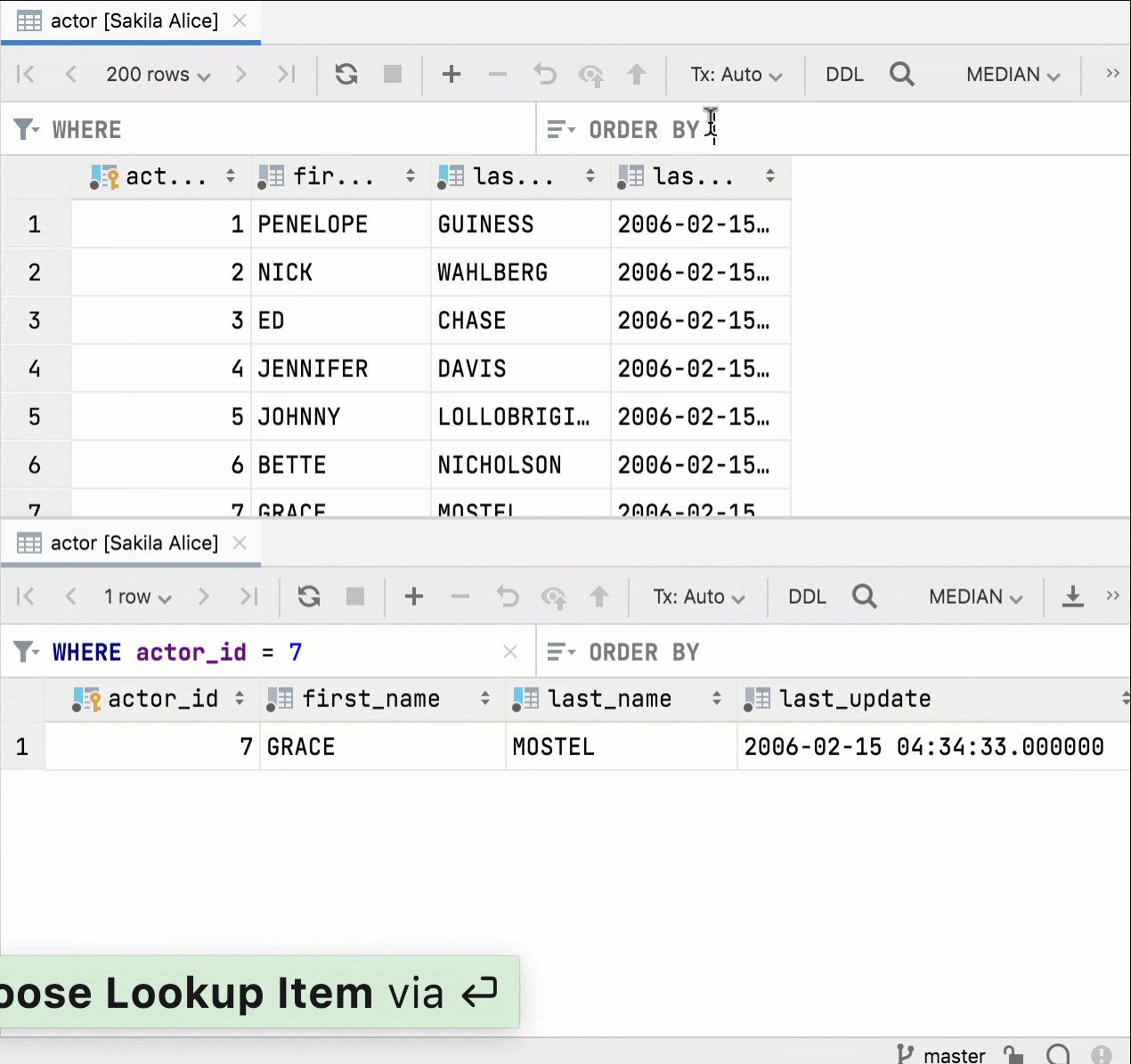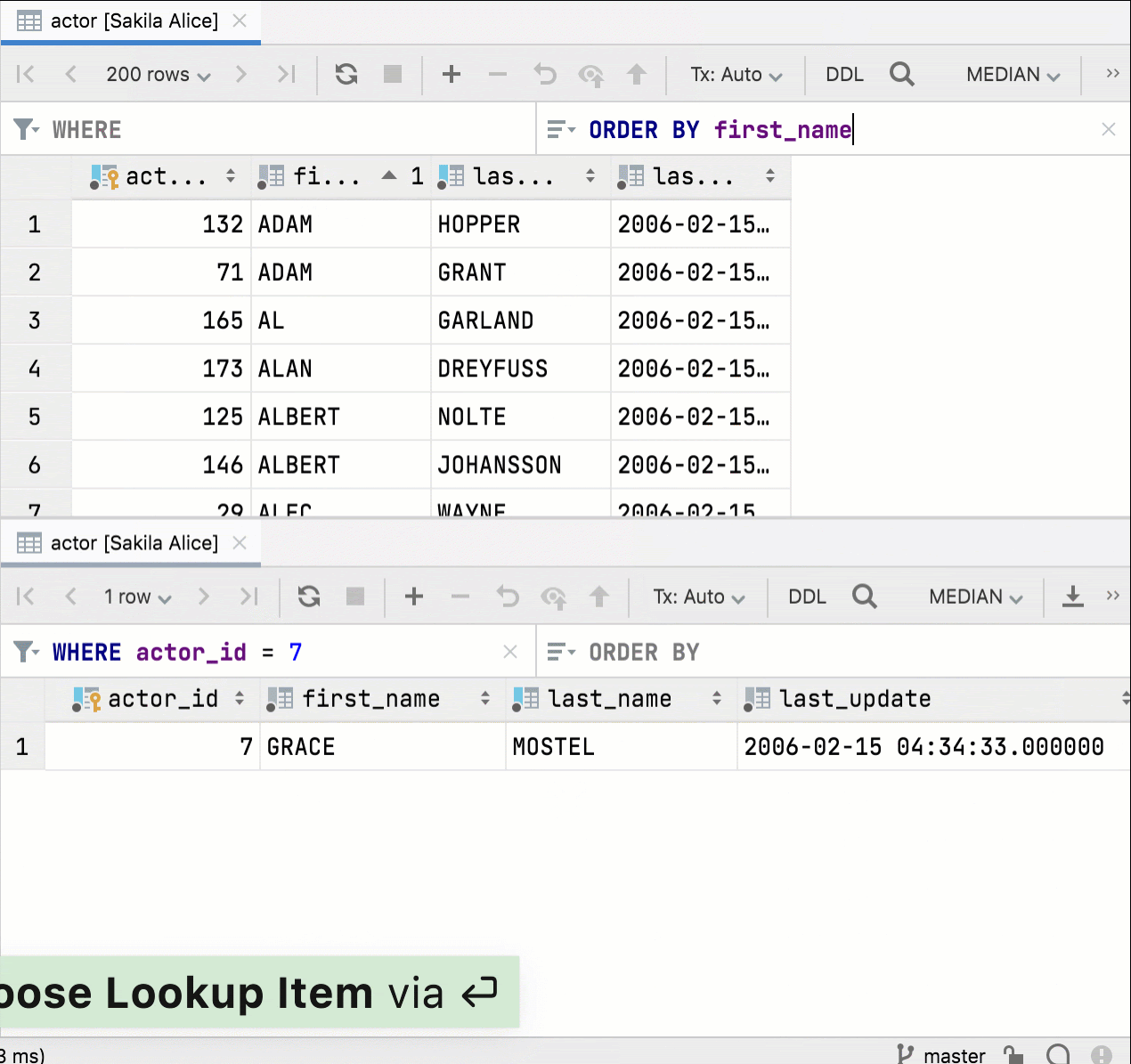
Si vous fractionnez l'éditeur et ouvrez la même table, les éditeurs de données seront désormais complètement indépendants. Vous pouvez définir différentes options de filtrage et de tri pour chacune d'entre elles. Auparavant, le filtrage et le tri étaient synchronisés, ce qui était évidemment inutile.
Police personnalisée
Vous pouvez choisir la police dédiée pour consulter les données sous Base de données | Vues de données | Utilisez une police personnalisée.
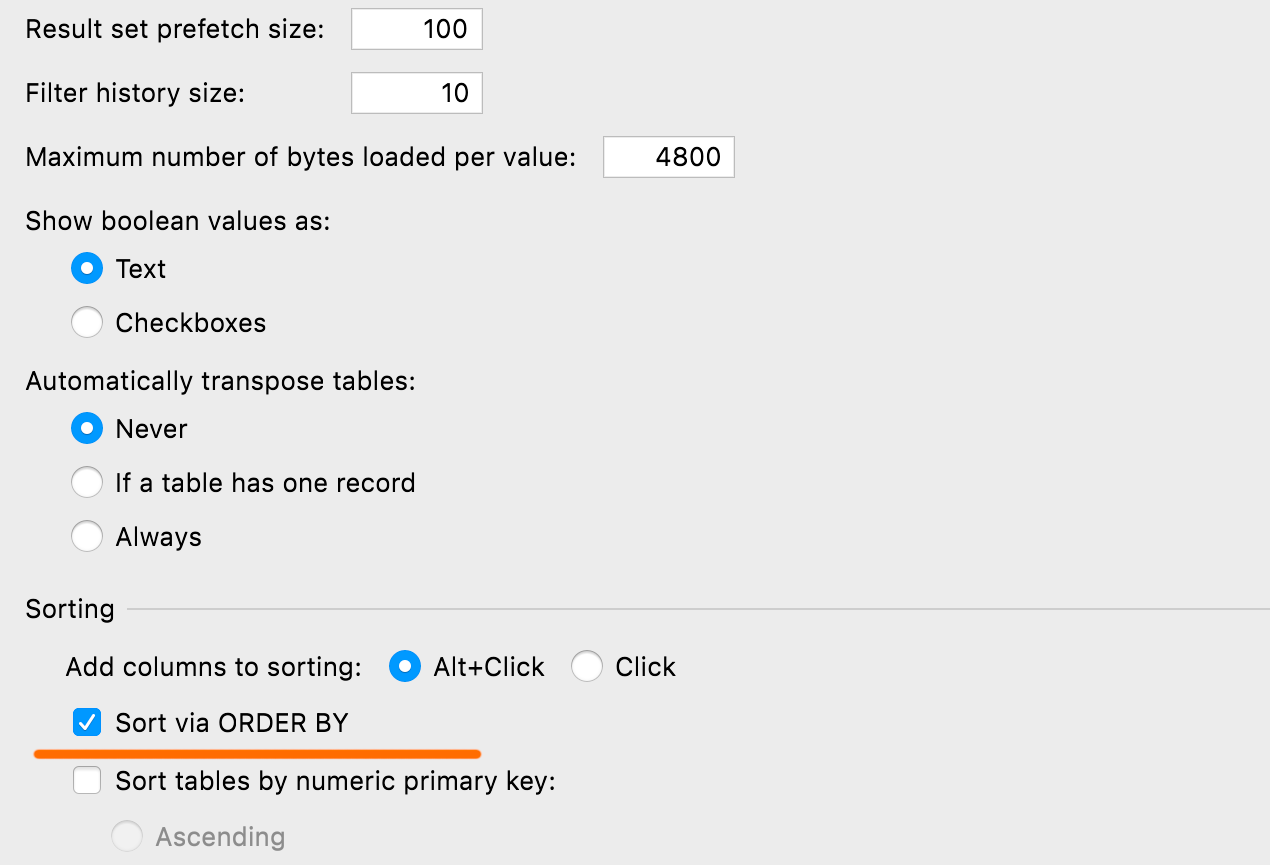
Paramétrage du tri par défaut
Vous pouvez définir la méthode de tri qui sera utilisée par défaut pour les tables : via ORDER BY ou côté client (qui n'exécute aucune nouvelle requête et trie uniquement la page en cours). Le paramètre se trouve sous Base de données | Vues de données | Tri | Trier via ORDER BY.
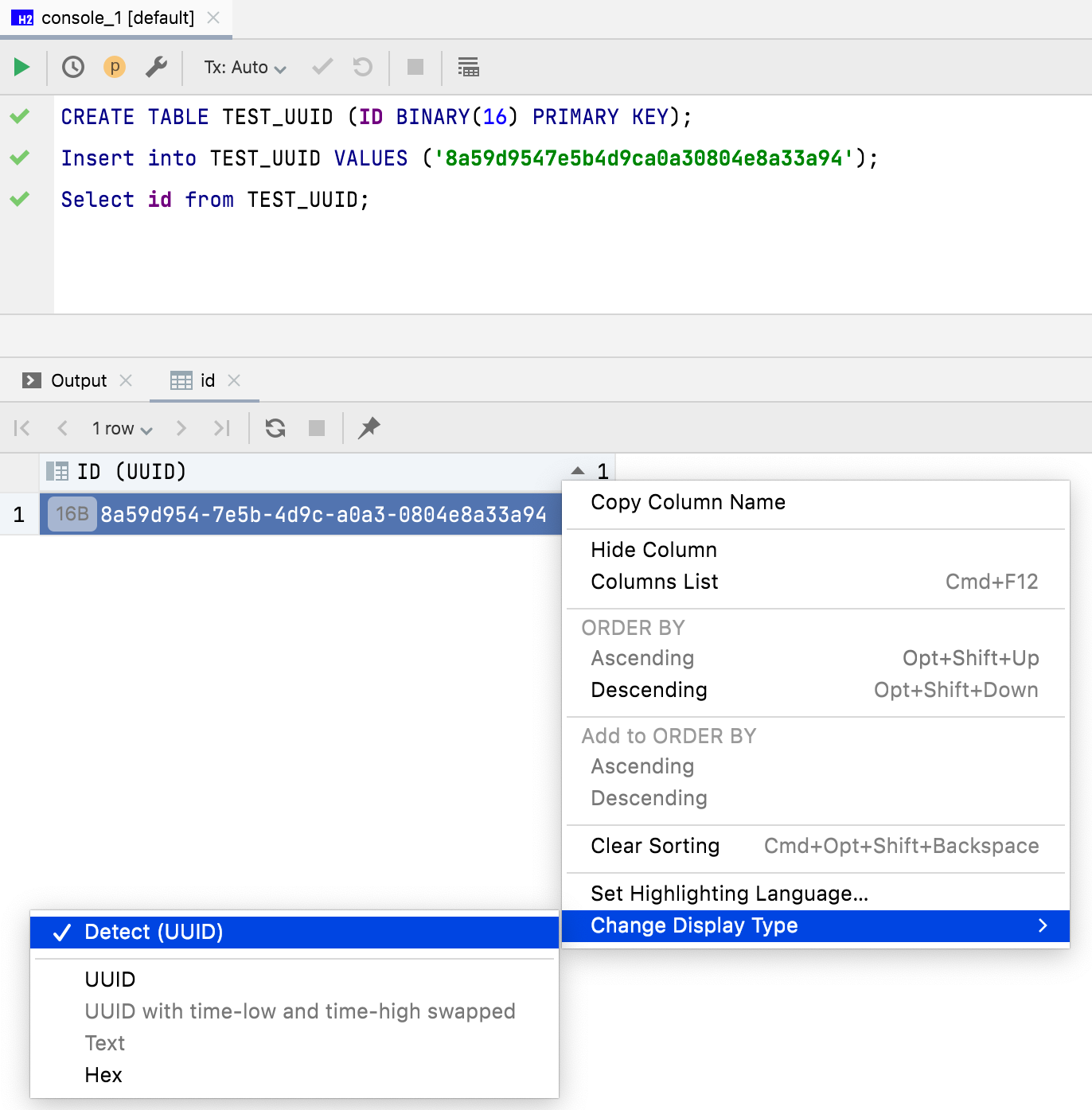
Mode d'affichage des données binaires
Les données de 16 octets sont désormais affichées sous forme d'UUID par défaut. Vous pouvez également personnaliser l'affichage des données binaires dans la colonne.
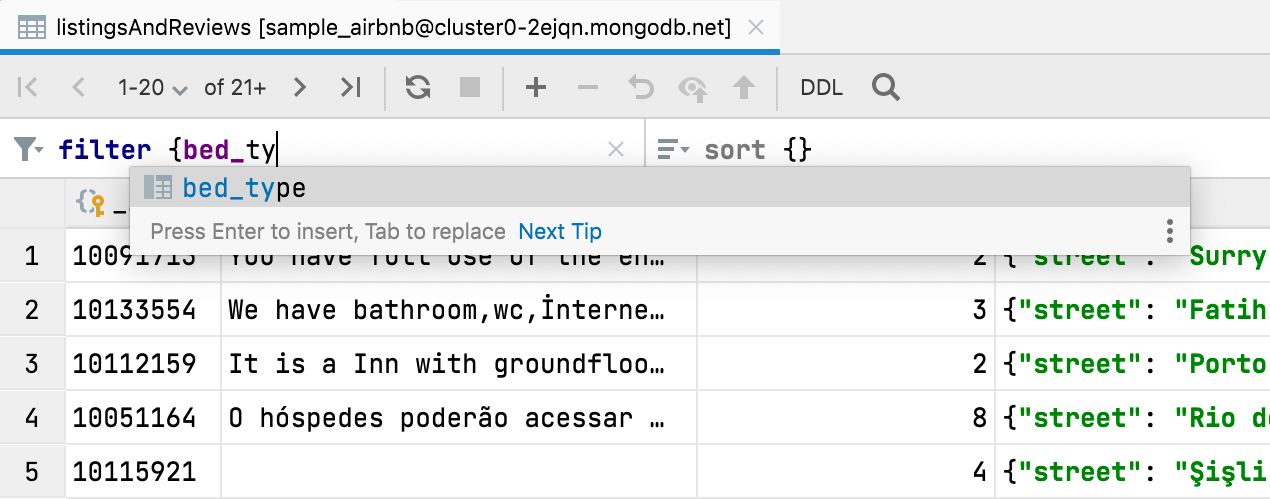
[MongoDB] Complétion de code pour filter {} et sort {}
La complétion de code fonctionne désormais lors du filtrage des données dans les collections MongoDB.
Base de données dans le système de contrôle de version (VCS)
TLDR
Cette version est la suite logique de la précédente, qui a introduit la possibilité de générer une source de données DDL basée sur une source réelle. Maintenant, ce flux de travail est entièrement pris en charge. Vous pouvez :
- Générer une source de données DDL à partir d'une source réelle
- Utilisez la source de données DDL pour mapper la source réelle
- Les comparer et les synchroniser dans les deux sens
Pour rappel, une source de données DDL est une source de données virtuelle dont le schéma est basé sur un ensemble de scripts SQL. Le stockage de ces fichiers dans le système de contrôle de version est un moyen de conserver votre base de données sous le VCS.
Base de données dans le VCS : workflow pas à pas
Jetons un coup d'il à l'ensemble du processus. Imaginez que deux développeurs, Alice et Bob, souhaitent que leurs schémas de source de données soient synchronisés via GitHub.
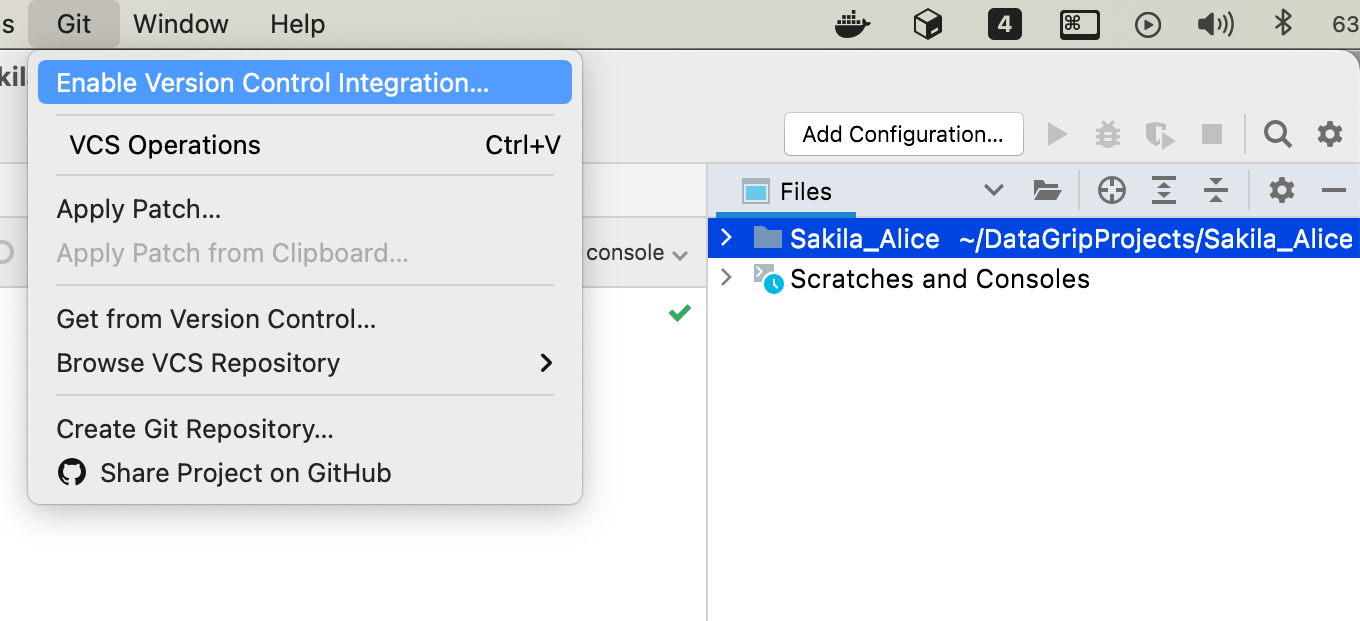
JetBrains conseille aux utilisateurs de stocker le dossier racine du projet dans le VCS. Alice et Bob synchroniseront leurs projets, qui contiennent les sources de données DDL pour la base de données Sakila. Ils ont tous les deux leurs sources de données locales, mais ils souhaitent les synchroniser via VCS.
Alice active l'intégration du contrôle de version sur un dossier racine du projet, qui est généralement automatiquement affiché dans la fenêtre d'outil Fichiers.
Elle crée ensuite un dossier sakila_repo, qu'elle utilisera comme une représentation de schéma à synchroniser via VCS.
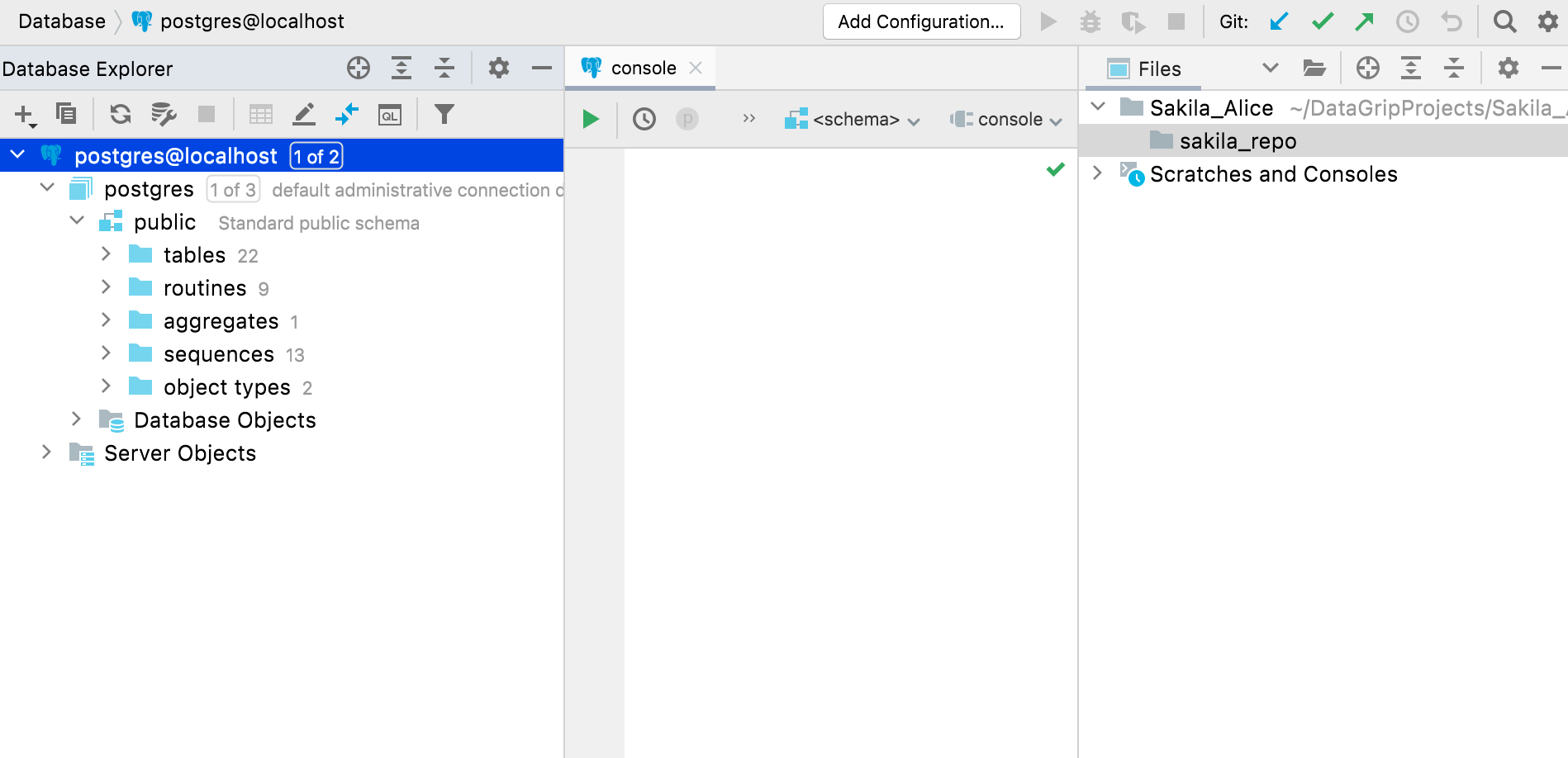
Tout d'abord, Alice doit créer la source de données DDL à l'aide de l'action Dump to DDL data source. Ce sera un miroir de schéma basé sur un fichier de la source de données réelle. Son nom est Sakila Alice DDL.
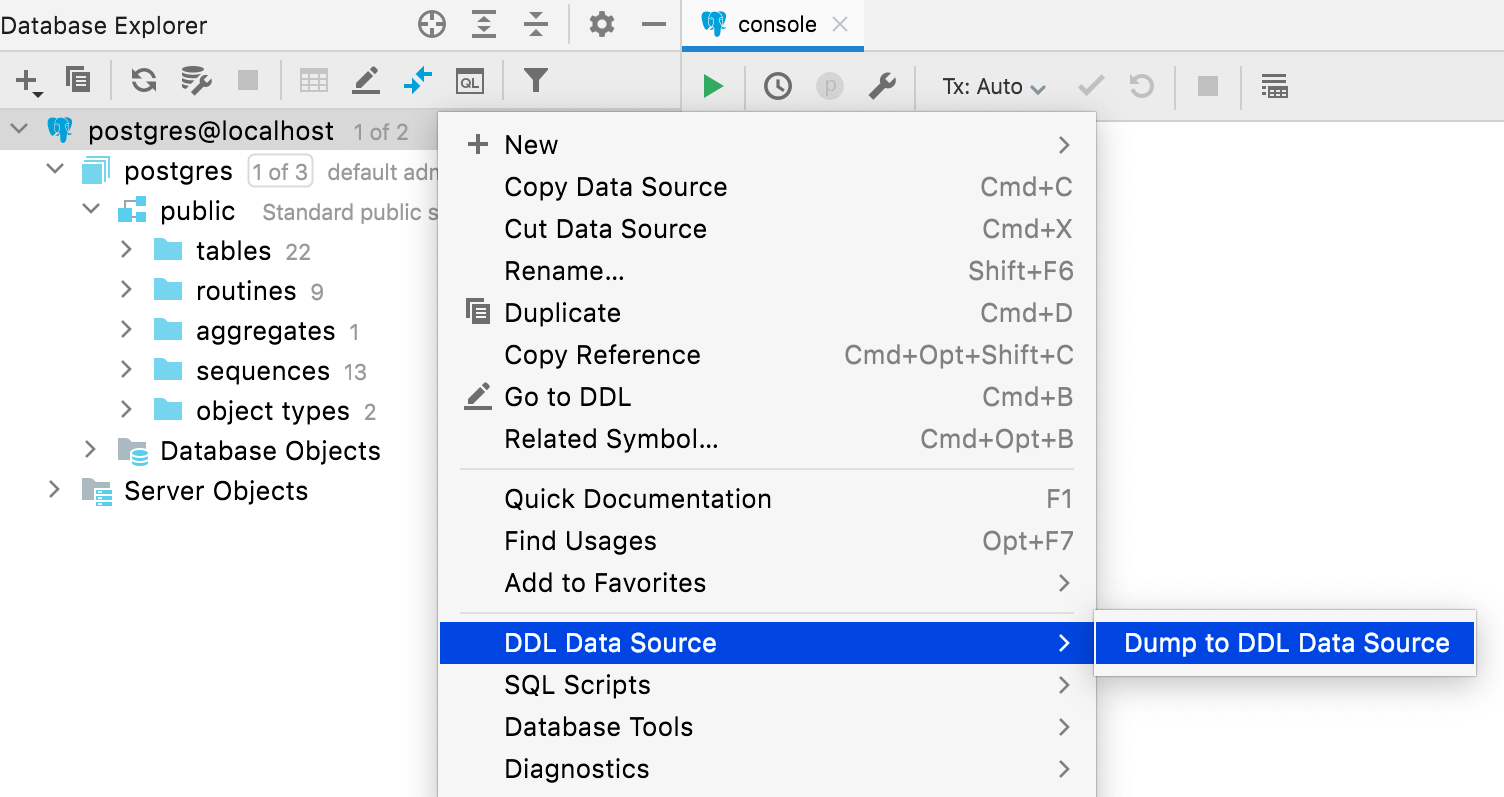
Lors de la création d'une source de données DDL, il est nécessaire de spécifier que les fichiers seront placés dans le dossier sakila_repo.
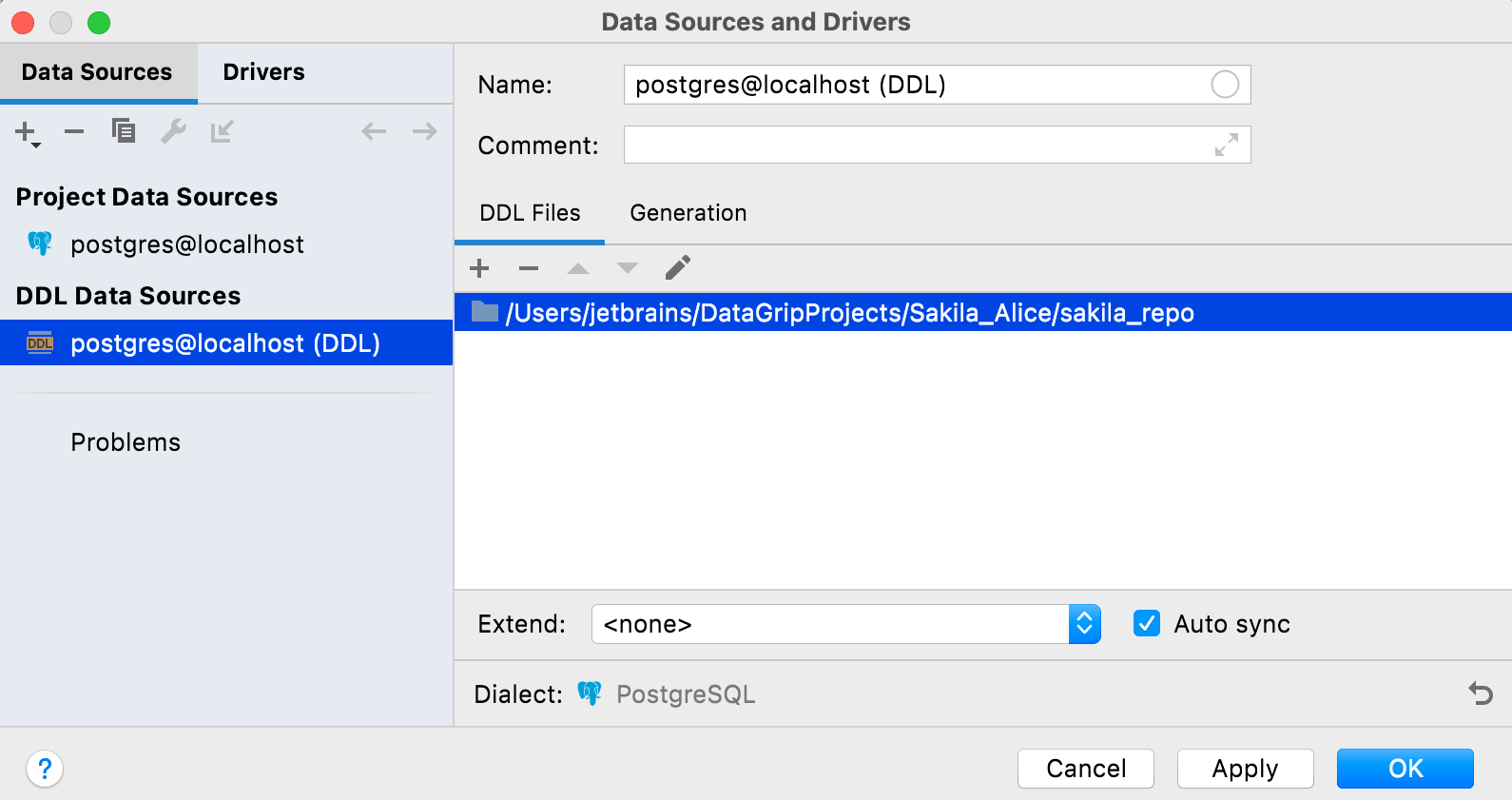
DataGrip demande si Alice souhaite ajouter de nouveaux fichiers à Git, et c'est effectivement ce qu'elle fait.
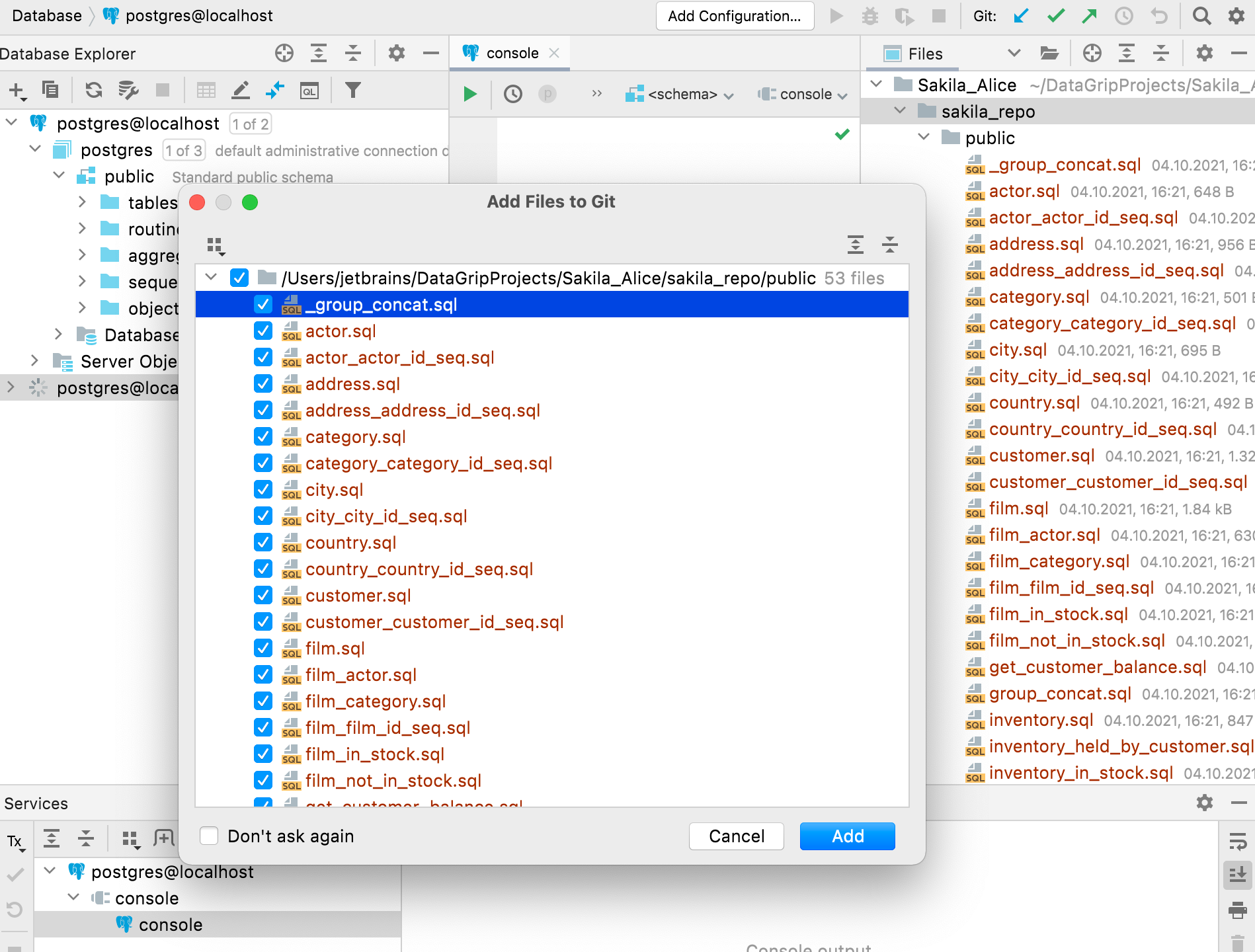
Maintenant, le projet, ainsi que le dossier sakila_repo, peuvent être validés et poussés vers le référentiel GitHub. Alice n'a pas encore défini le référentiel distant. Cela peut être fait à l'avance ou lorsque le projet est poussé.
Terminé !
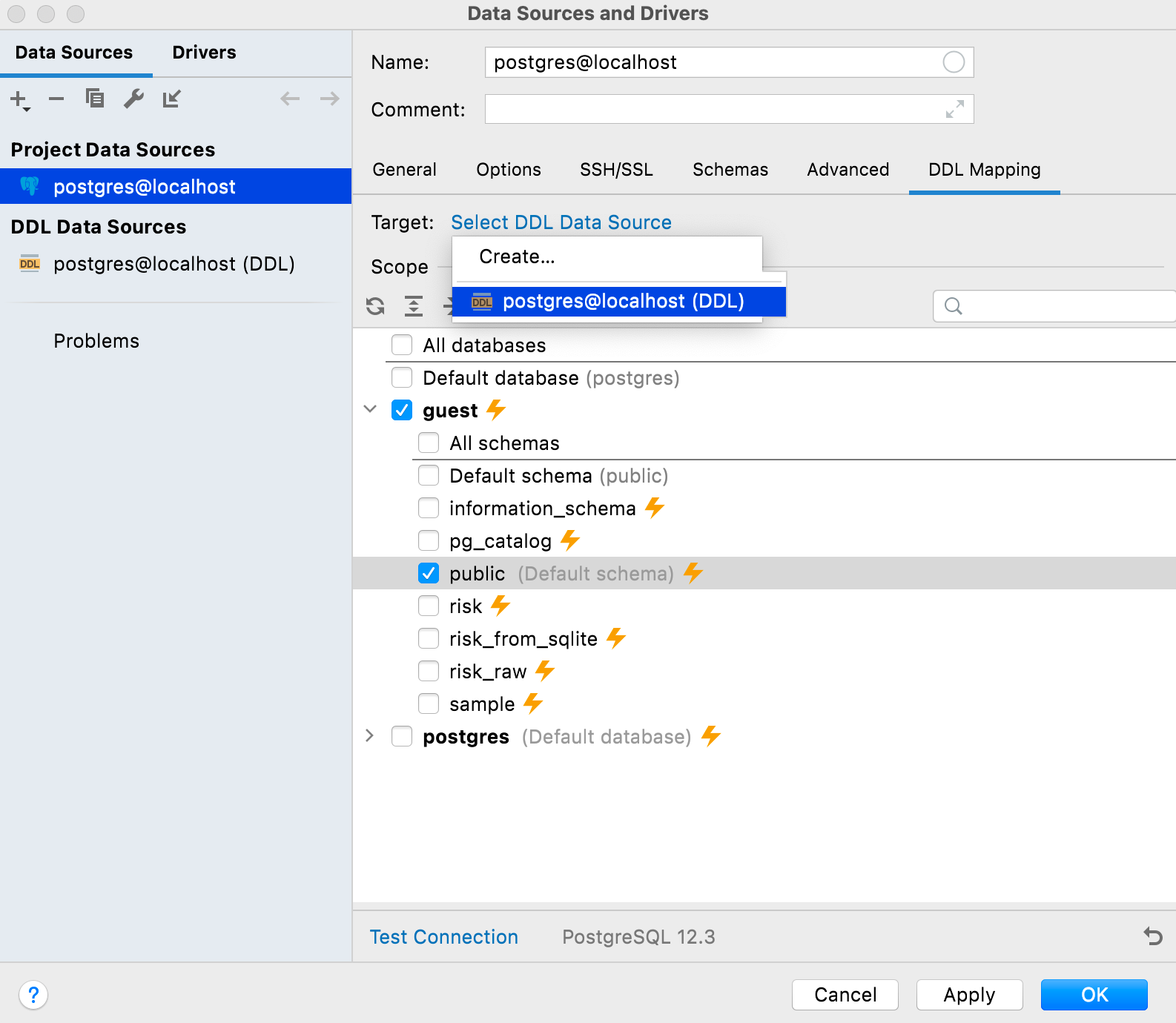
Bob clone le projet à partir de GitHub et dispose désormais de la même connexion locale et de la même source de données DDL, qui peuvent être synchronisées via VCS. Il lui suffit de mapper sa source de données locale en utilisant celle du DDL. Cela doit être fait dans l'onglet Mappage DDL des propriétés de la source de données.
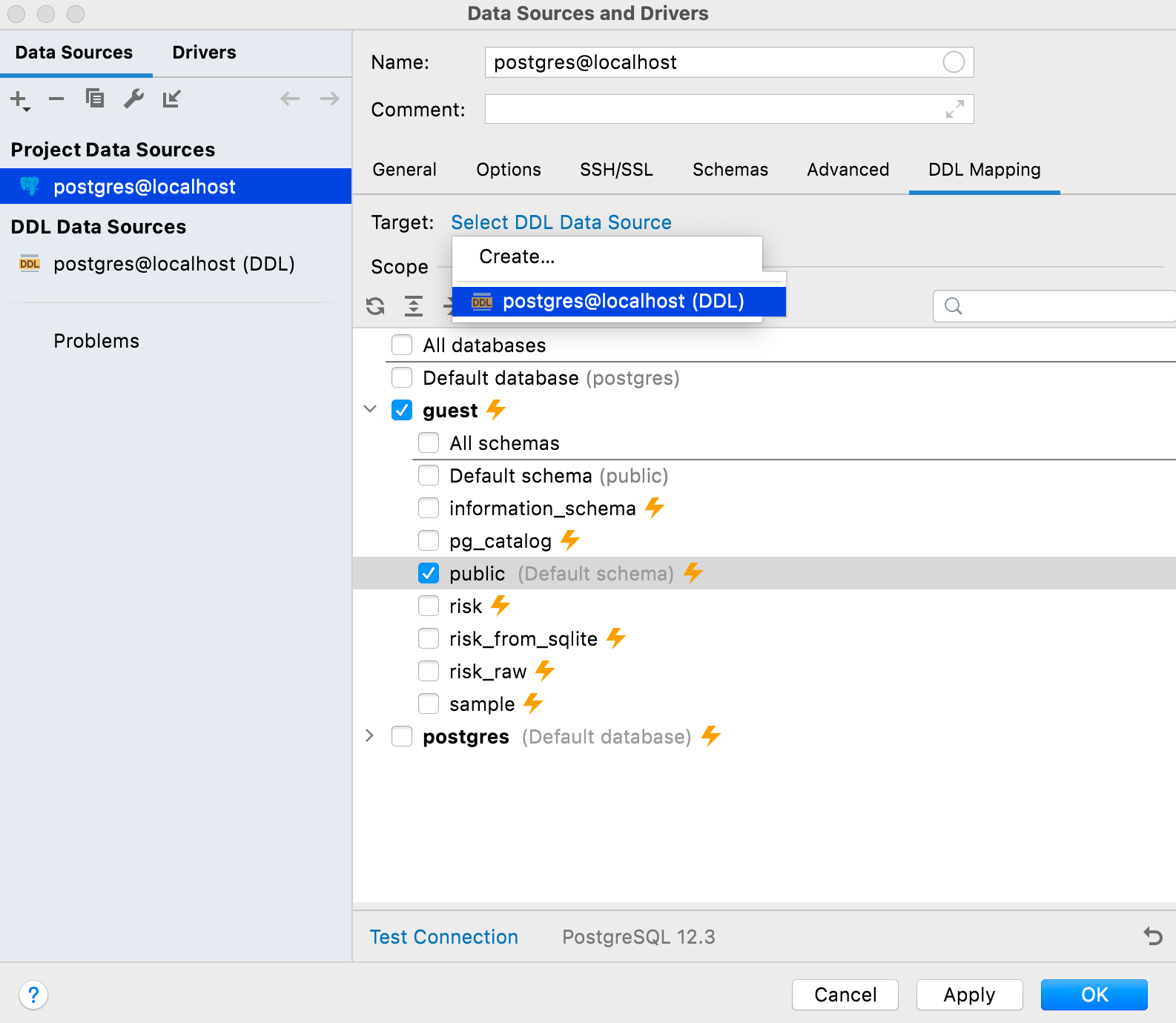
Maintenant, la source de données DDL représente la version du référentiel et la source de données locale est toujours locale. Ainsi, pour les synchroniser, Bob doit aller dans le menu contextuel de la source de données et sélectionner DDL data source | Apply from postgres@localhost (DDL).
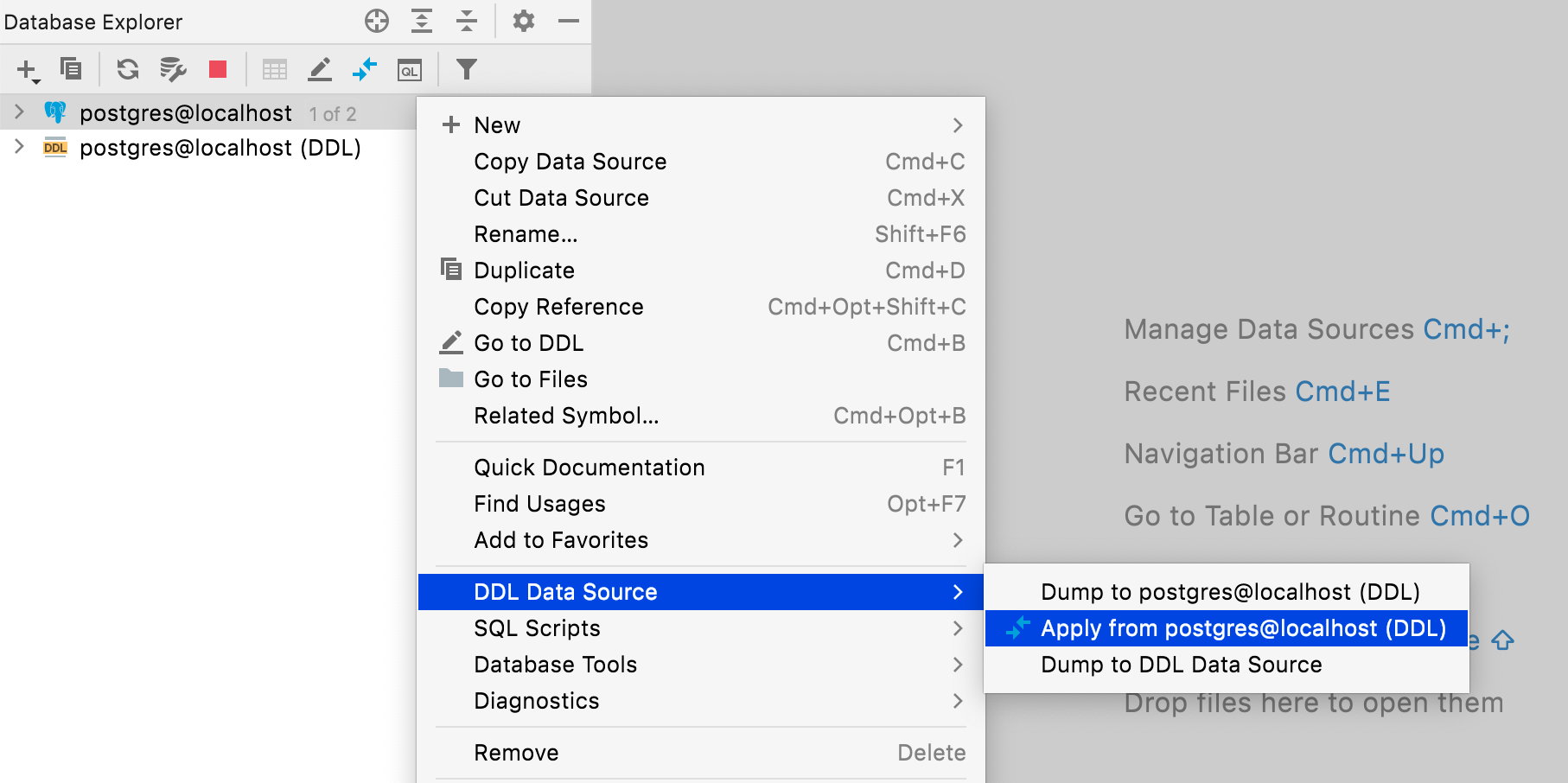
La boîte de dialogue de migration s'ouvre et Bob doit cliquer sur Apply Right to Left, et les sources de données sont synchronisées.
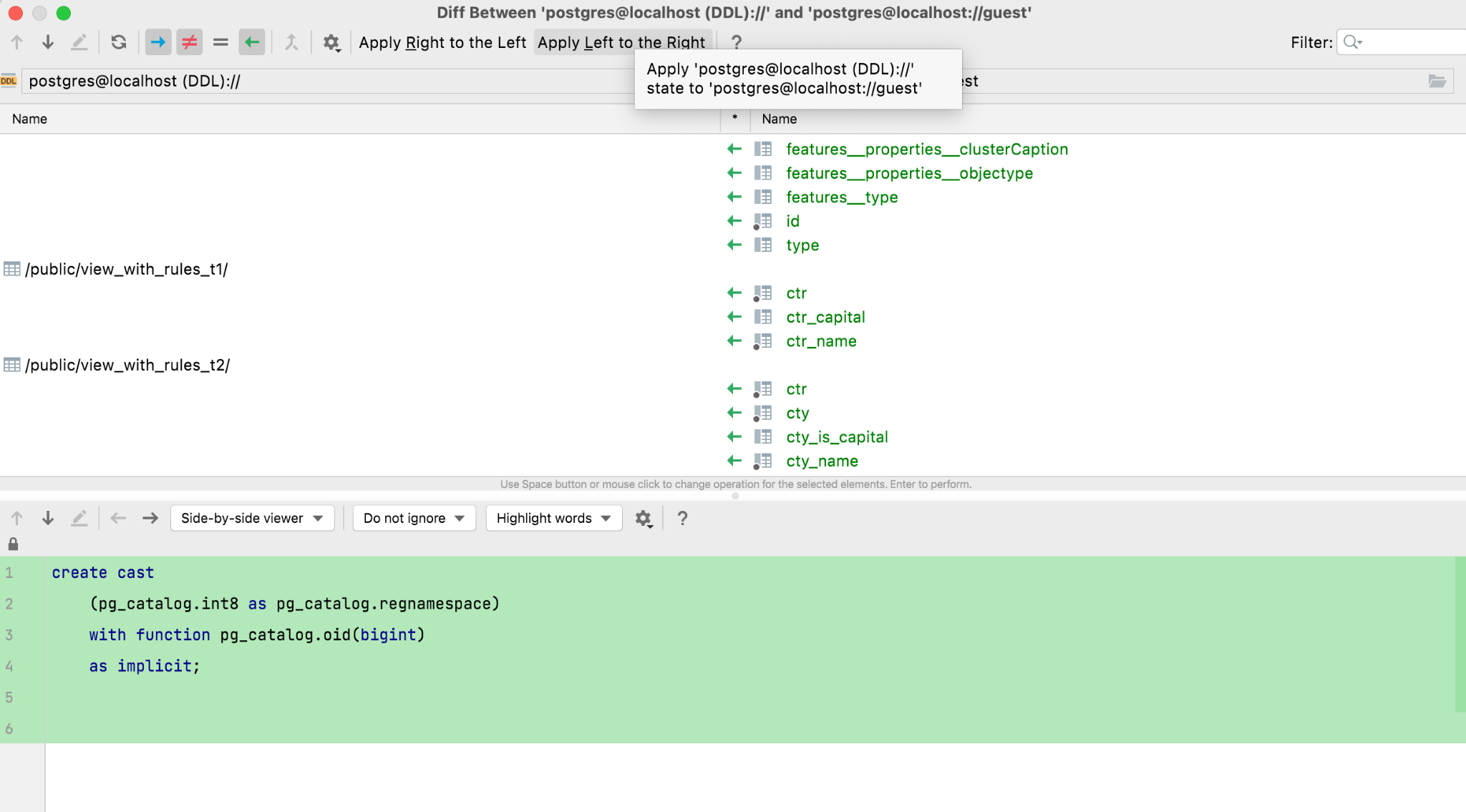
Bientôt, cette boîte de dialogue de migration sera complètement retravaillée, donc dans la version stable, il y aura un moyen plus pratique et plus puissant de migrer d'une source de données à une autre.
Actions liées aux fichiers
Toutes les actions pour les fichiers sont également disponibles sur les éléments de source de données DDL. Par exemple, vous pouvez supprimer, copier ou valider des fichiers liés aux éléments de schéma uniquement à partir de l'explorateur de base de données.
Synchronisation automatique
Si cette option est activée, la source de données DDL sera automatiquement actualisée avec les modifications apportées aux fichiers correspondants. C'était déjà le comportement par défaut, mais vous avez maintenant la possibilité de le désactiver.
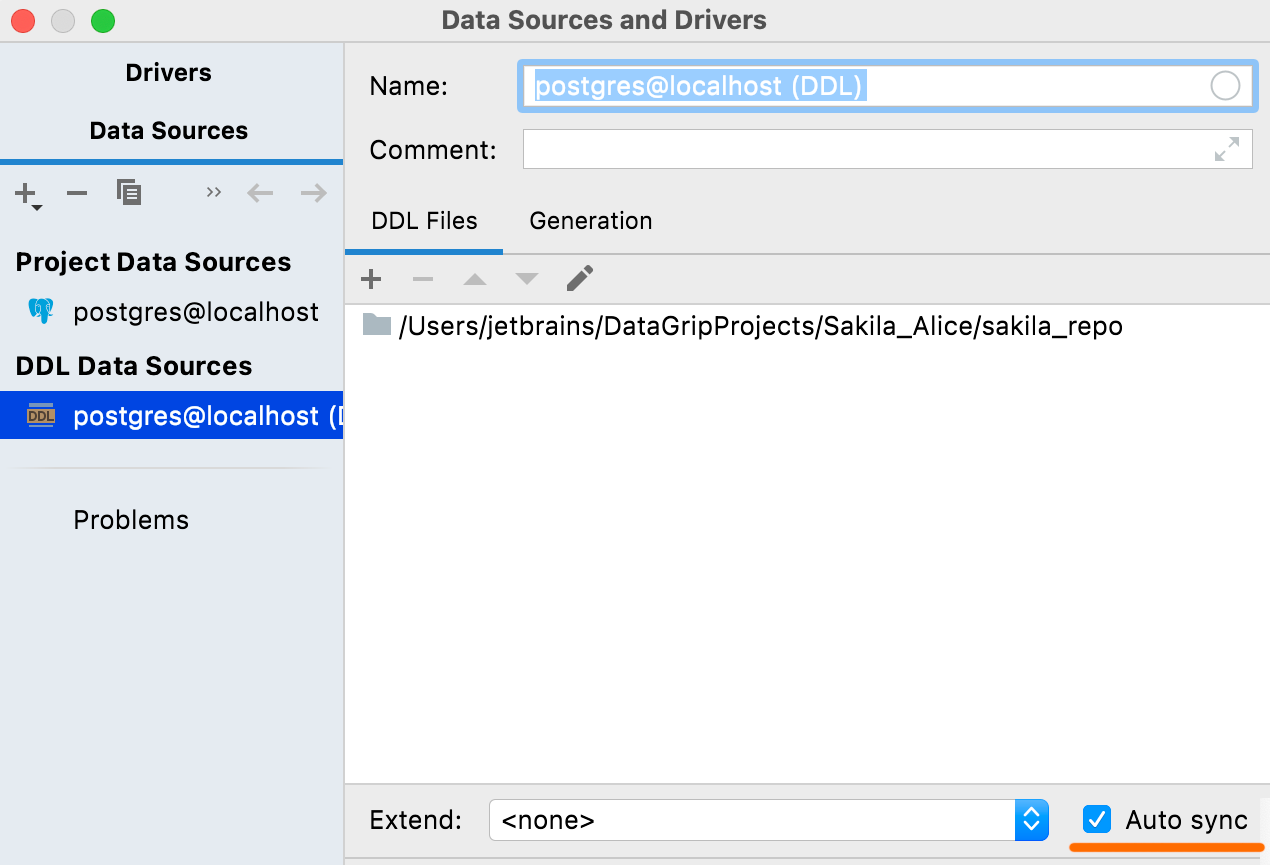
Chemin de recherche initial
Dans cette interface utilisateur, vous pouvez définir des noms pour votre base de données et vos schémas, qui seront affichés dans la source de données DDL. Les scripts DDL ne contiennent généralement pas de noms, et dans ces cas, il y aura des noms factices pour les bases de données et les schémas par défaut.
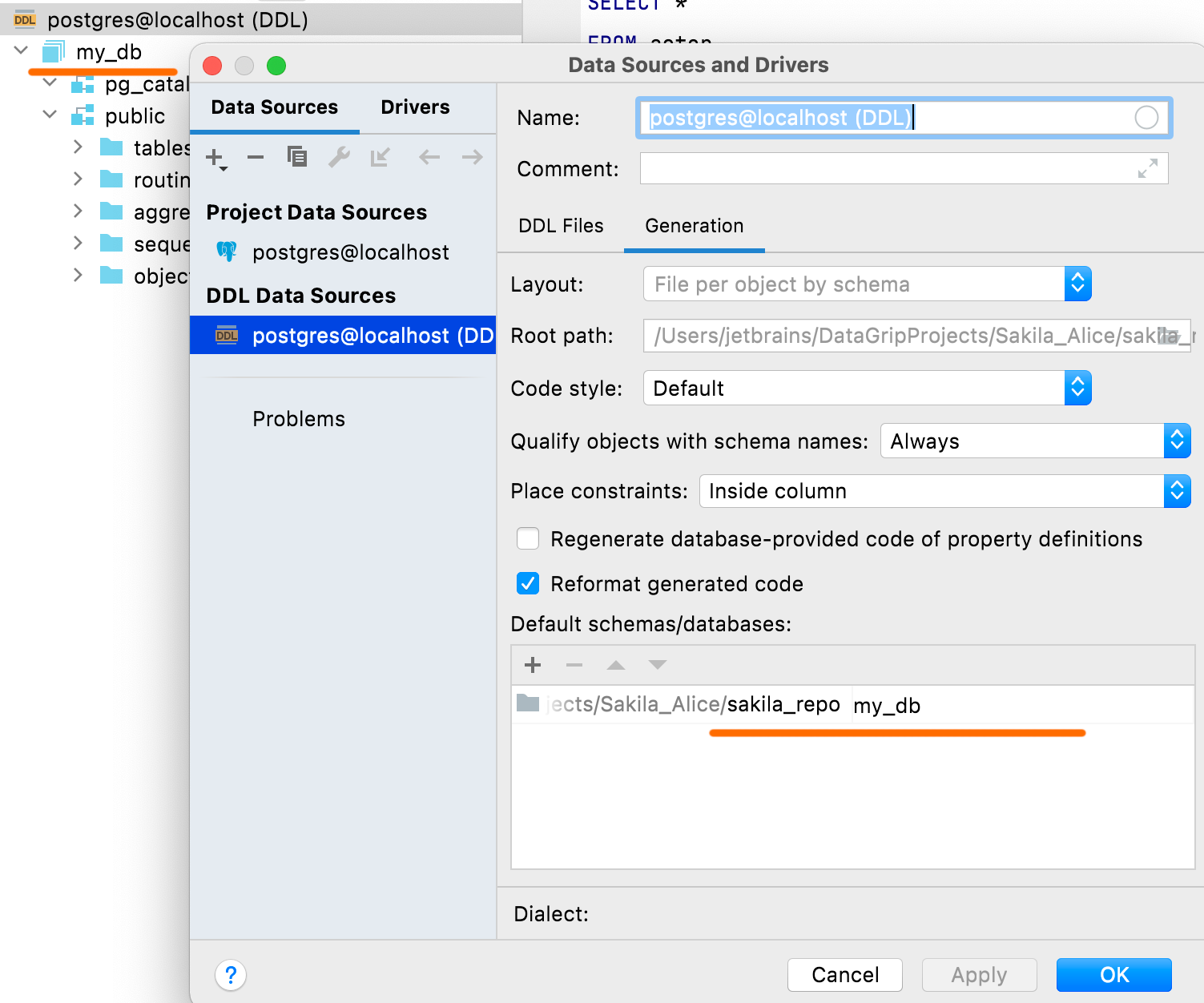
Connectivité
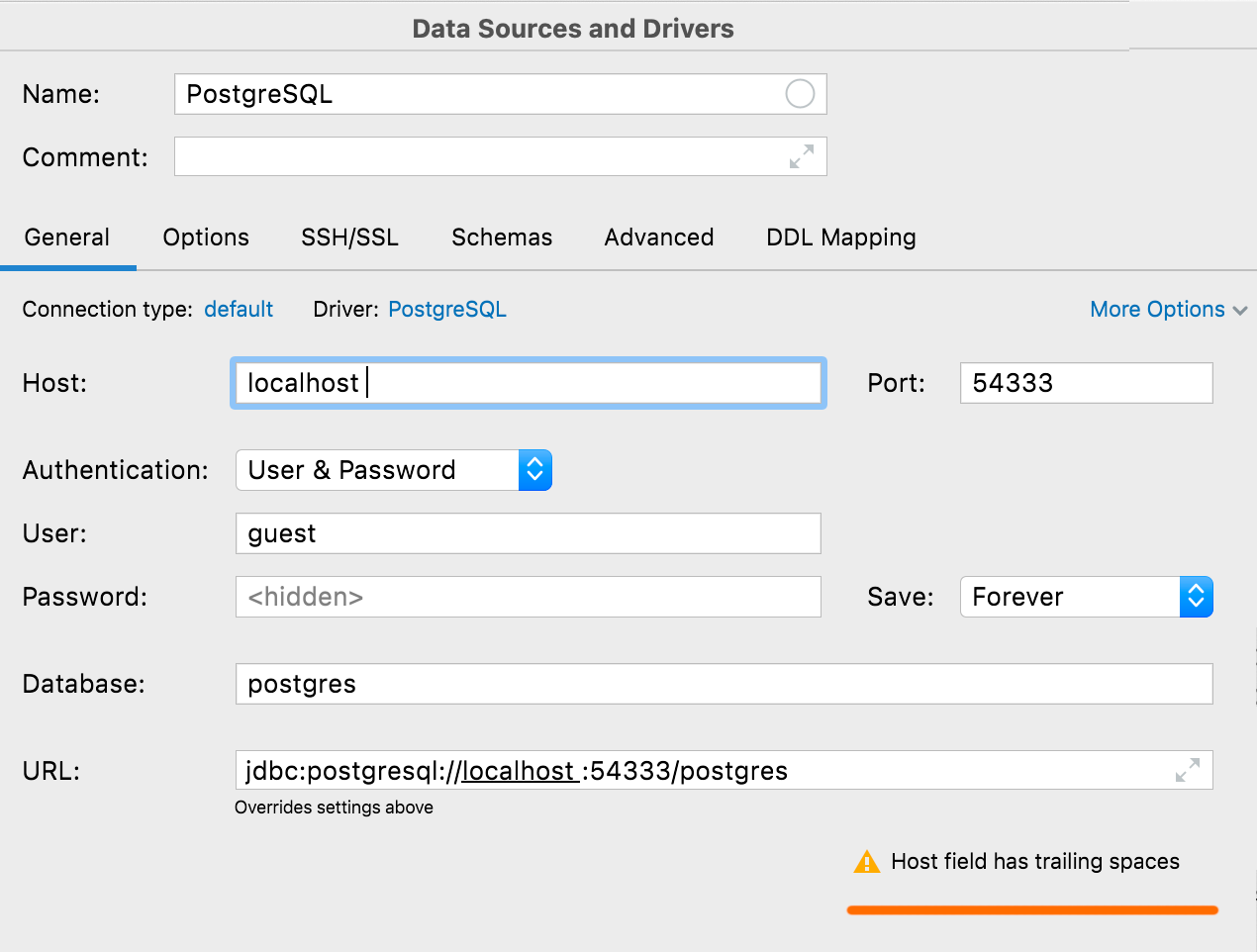
Avertissement d'espaces accidentels
Si une valeur, à l'exception du nom utilisateur ou du mot de passe, comporte des espaces de début ou de fin, DataGrip vous en avertira lorsque vous cliquerez sur Tester la connexion.
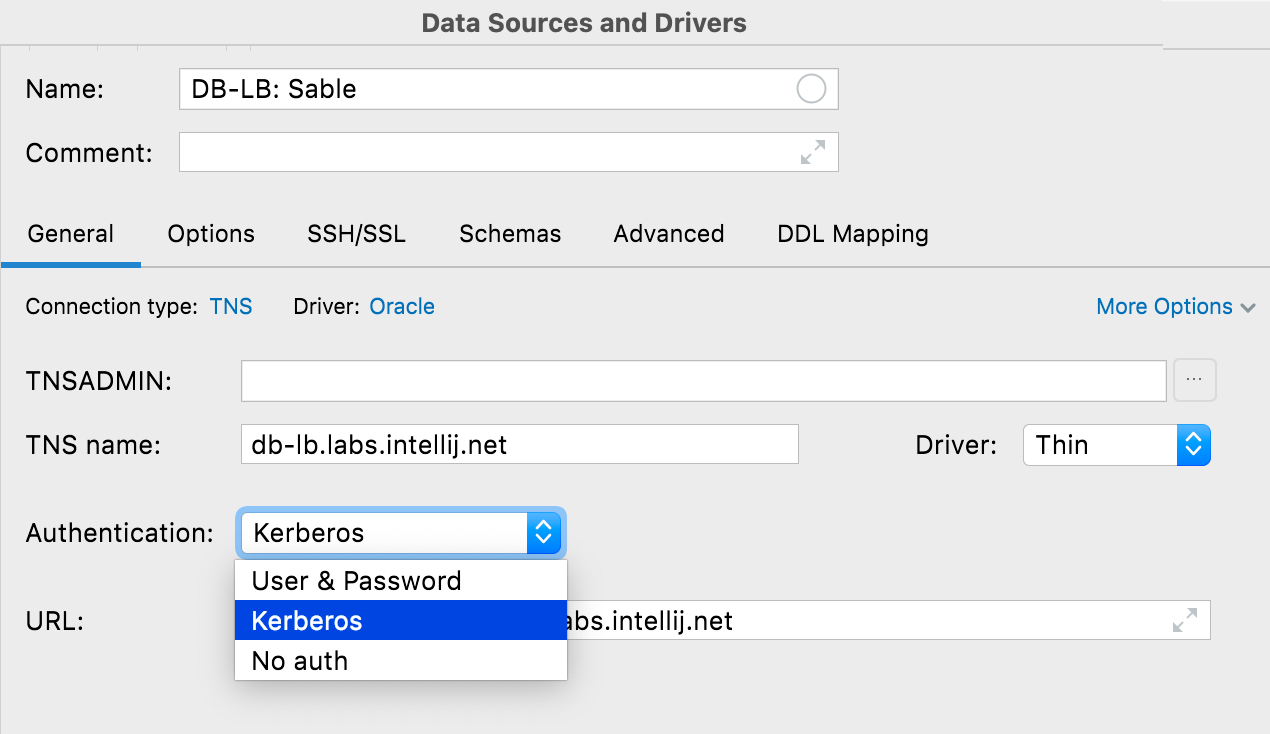
[Oracle, SQL Server] Authentification Kerberos
Il est désormais possible d'utiliser l'authentification Kerberos dans Oracle et SQL Server.
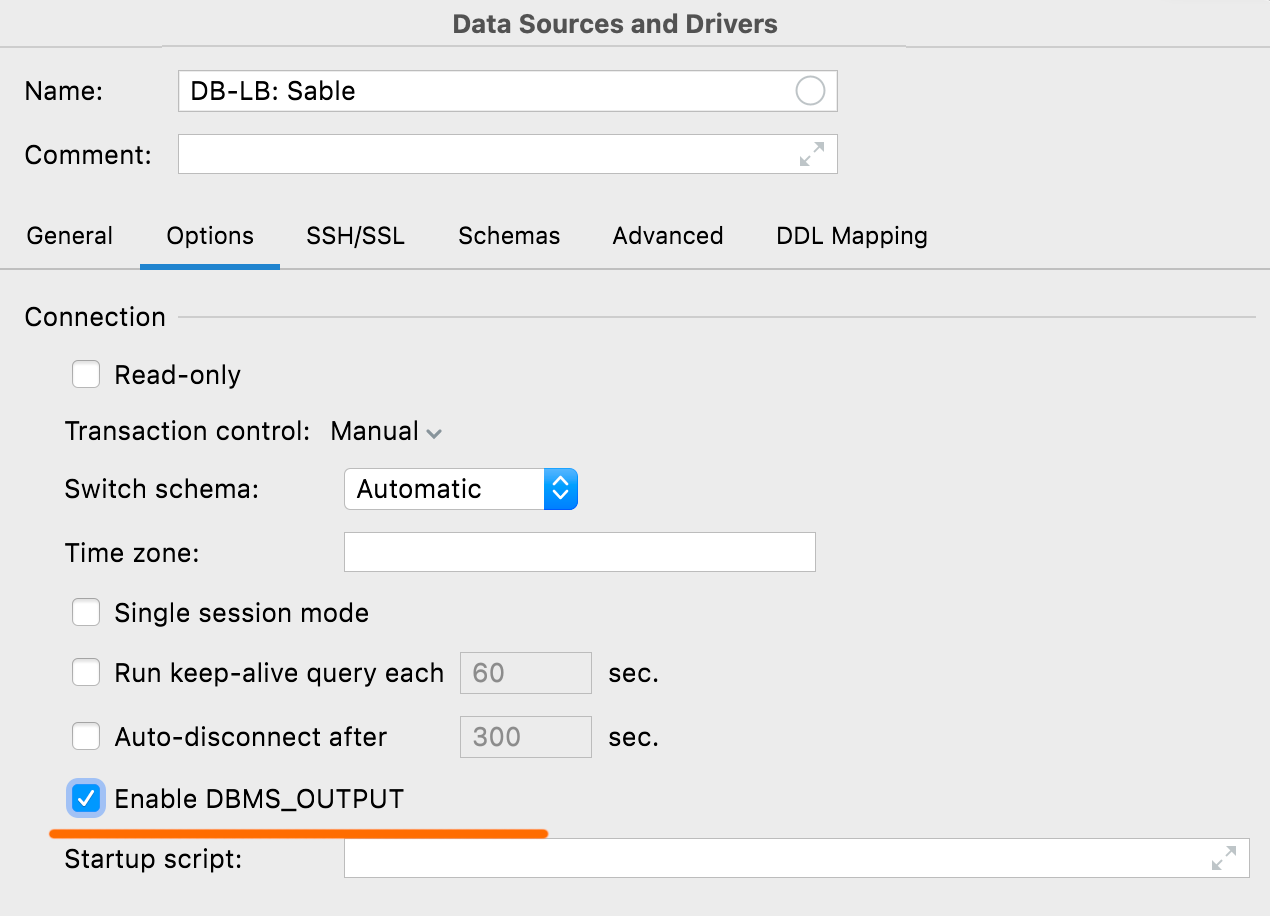
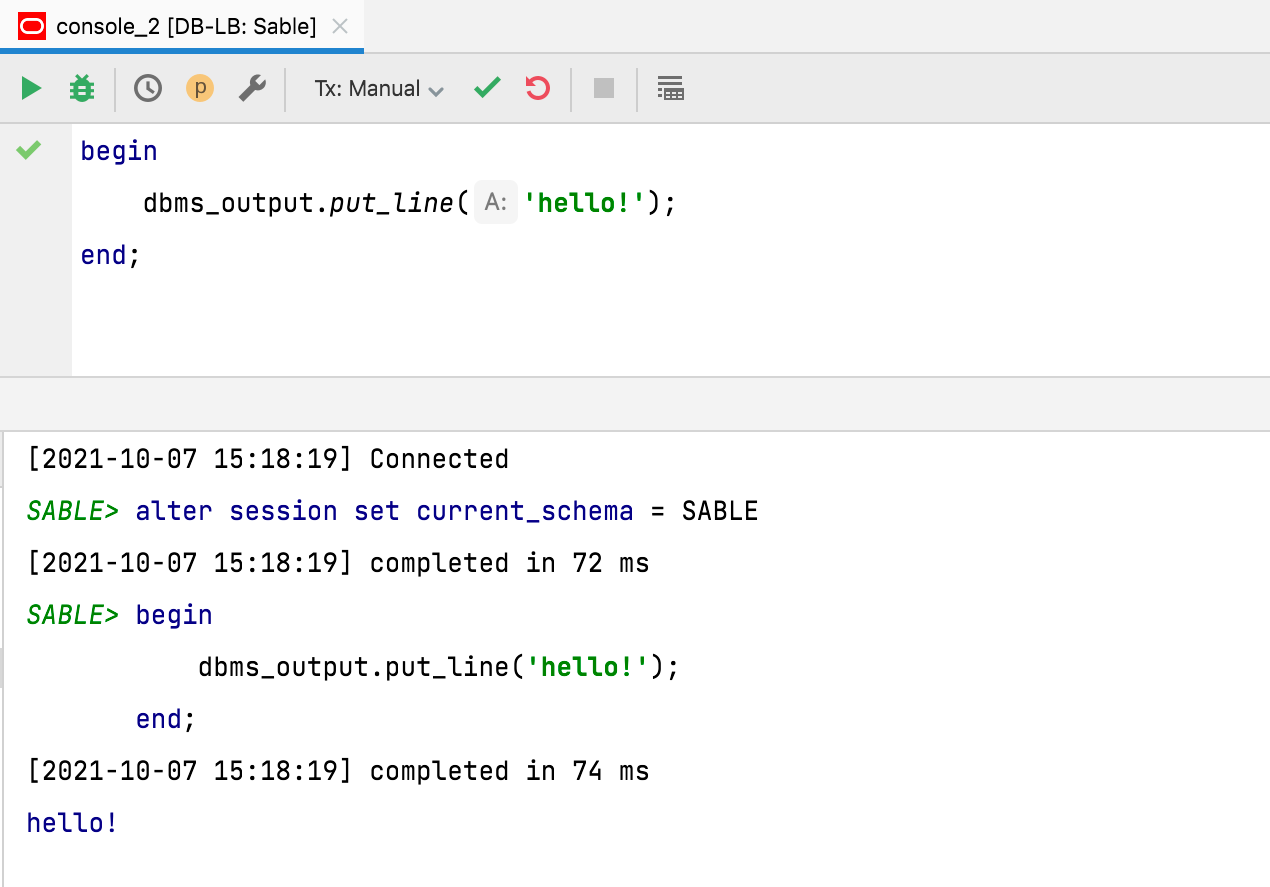
[Oracle, DB2] Activer DBMS_OUTPUT
Cette nouvelle option dans l'onglet Options vous permet d'activer DBMS_OUTPUT par défaut pour les nouvelles sessions.
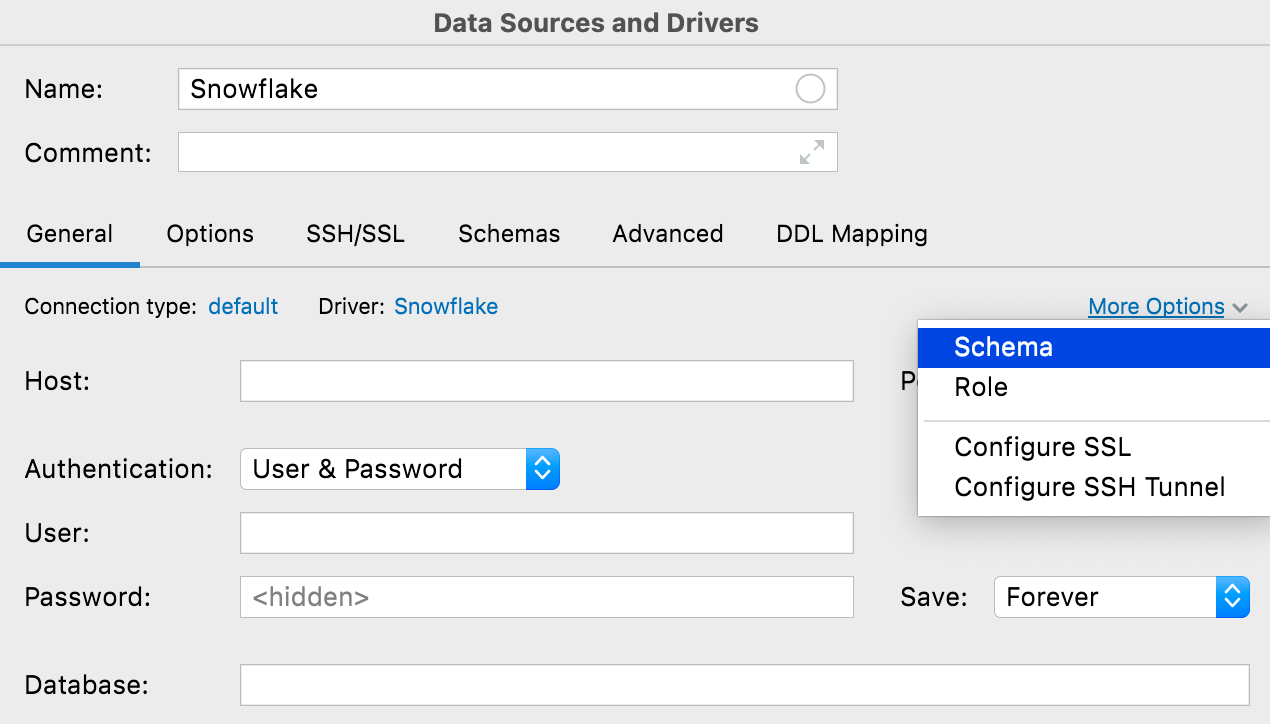
Bouton "Plus d'options"
JetBrains a introduit un bouton Plus d'options pour les cas où quelque chose d'inhabituel doit être configuré pour la connexion, mais qu'il n'est pas nécessaire d'encombrer l'interface utilisateur. Ces options incluent actuellement la possibilité d'ajouter des champs Schema et Role pour les connexions Snowflake et des boutons pour configurer SSH et SSL.
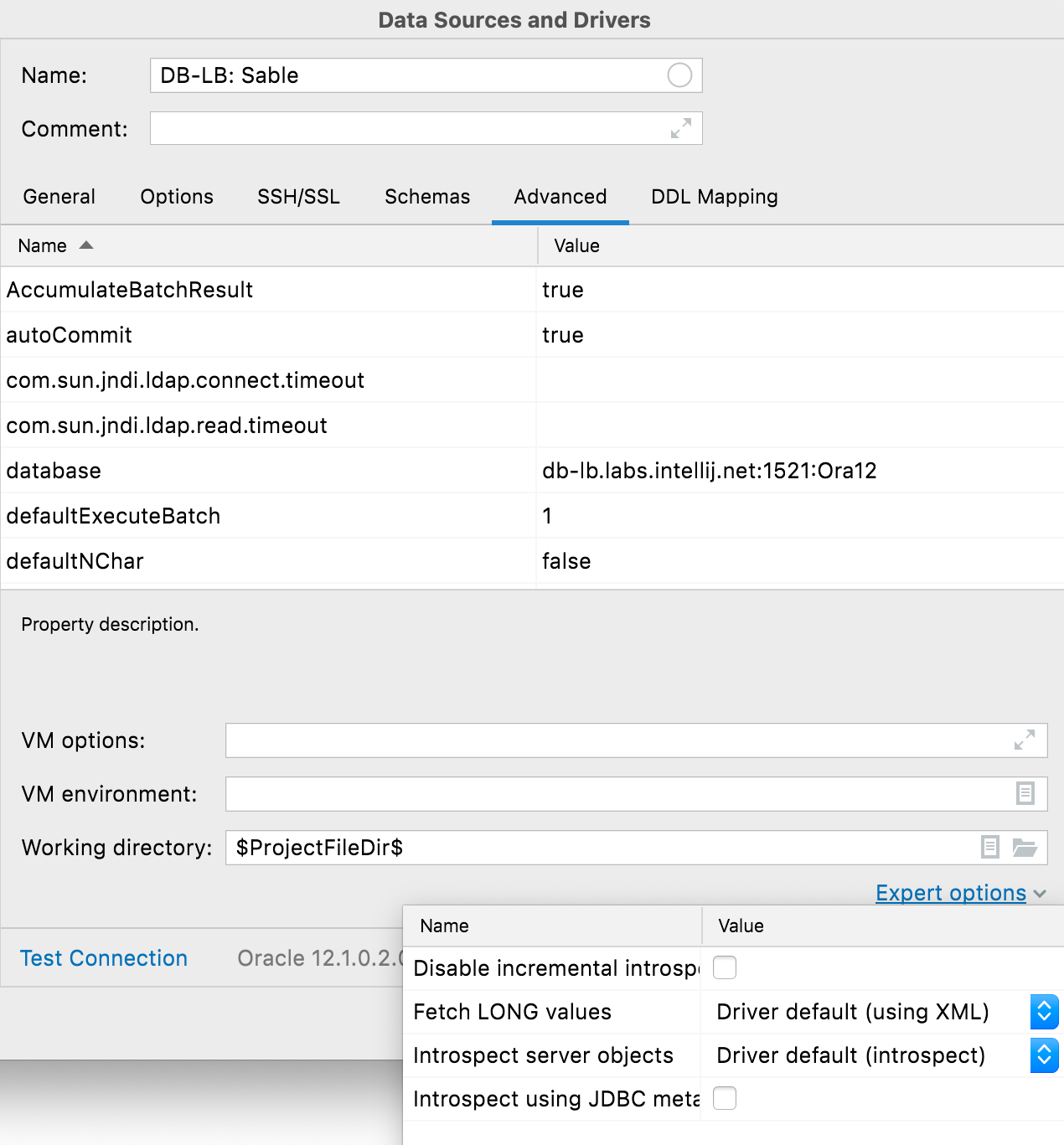
Options Expert
L'onglet Avancé comprend désormais une liste d'options Expert. En plus d'une option courante pour activer l'introspecteur JDBC (contacter le support de JetBrains avant de l'utiliser), il existe des options spécifiques à la base de données :
Oracle : désactiver l'introspection incrémentielle, récupérer les valeurs LONG, Introspecter les objets serveur.
SQL Server : désactiver l'introspection incrémentielle.
PostgreSQL (et similaire) : désactiver l'introspection incrémentielle, ne pas utilisez pas xmin dans les requêtes vers pgdatabase.
SQLite : enregistrer la fonction REGEXP.
MYSQL : utiliser SHOW/CREATE pour le code source.
Clickhouse : attribuer automatiquement un identifiant de session (sessionid).
Explorateur de bases de données
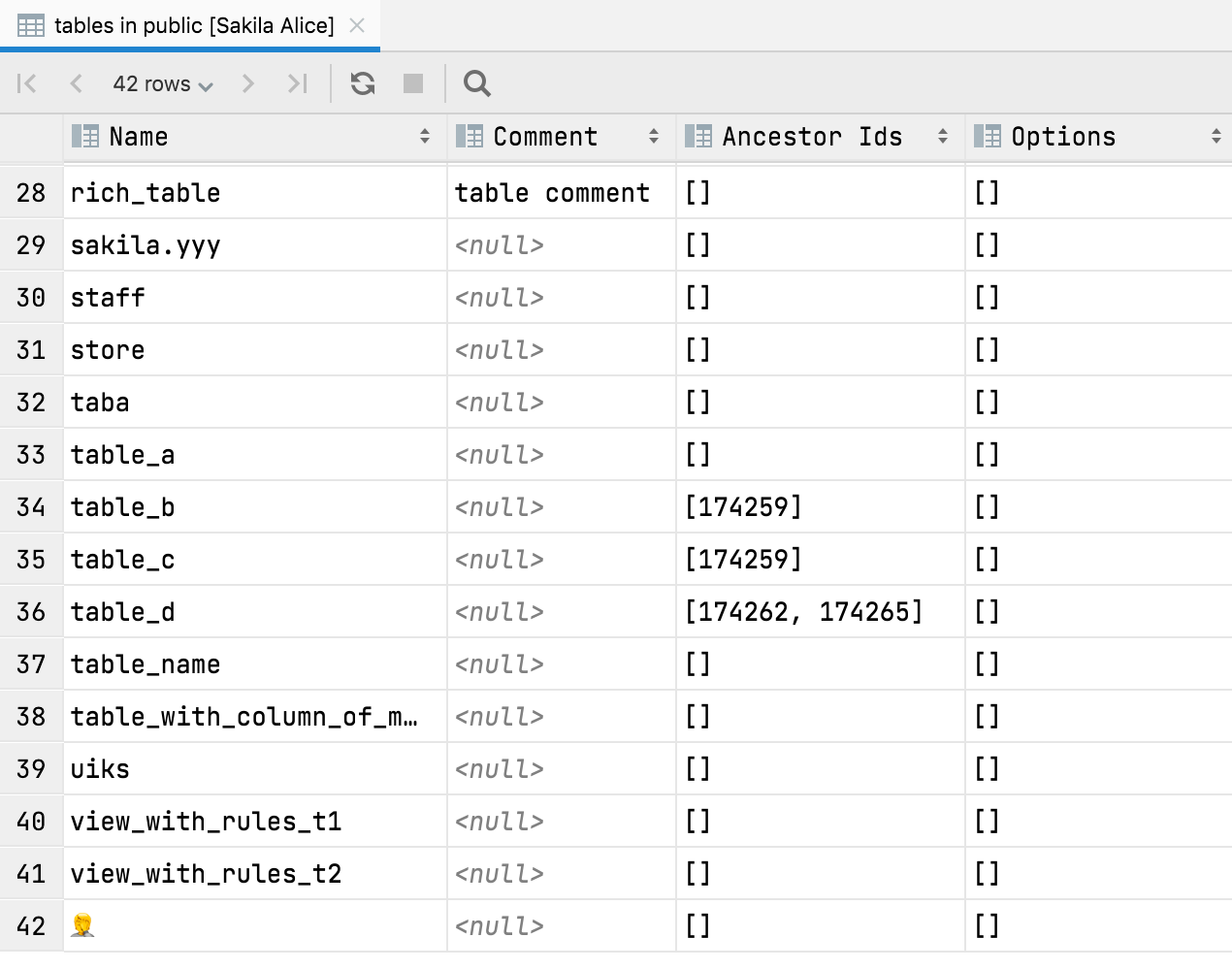
Vue tabulaire pour les nuds d'arborescence
Appuyer sur F4 sur n'importe quel nud de schéma vous permet de voir la vue tabulaire du contenu du nud. Par exemple, vous pouvez obtenir une vue de toutes les tables :
Ou les colonnes d'une table :
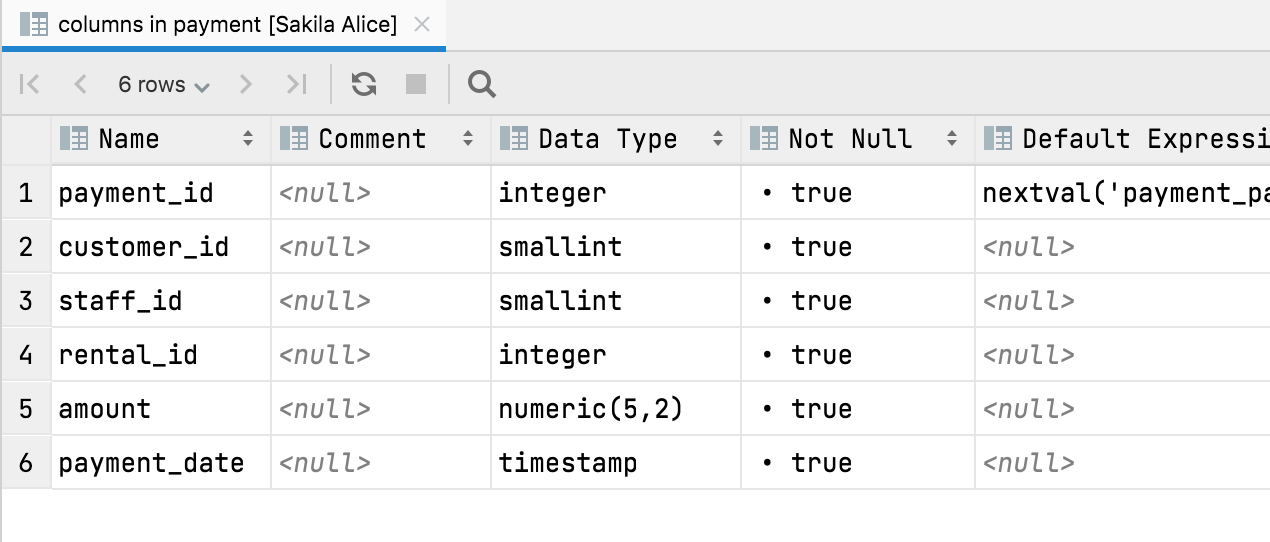
Toutes les fonctionnalités de la visionneuse de données sont disponibles ici : vous pouvez masquer/afficher des colonnes, exporter vers de nombreux formats et utiliser la recherche de texte.
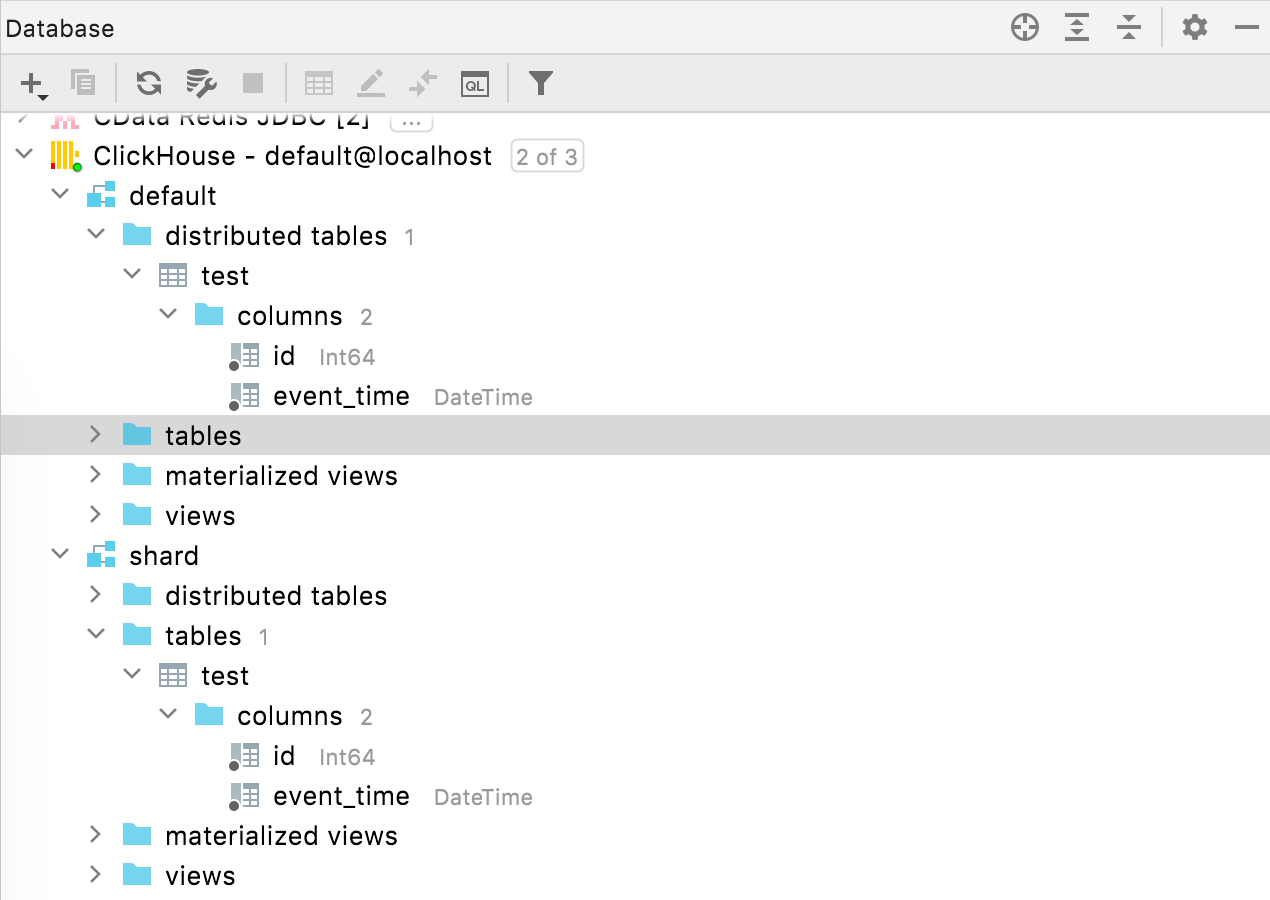
[Clickhouse] Tables distribuées
Les tables distribuées sont désormais placées sous un nud dédié dans l'explorateur de base de données
Console de requête
Horodatages en sortie masqués par défaut
Conformément à la demande des utilisateurs, les horodatages ne sont plus affichés par défaut pour la sortie d'une requête. Si vous souhaitez revenir au comportement précédent, vous pouvez ajuster le paramètre dans Base de données | Général | Afficher l'horodatage pour la sortie de la requête.
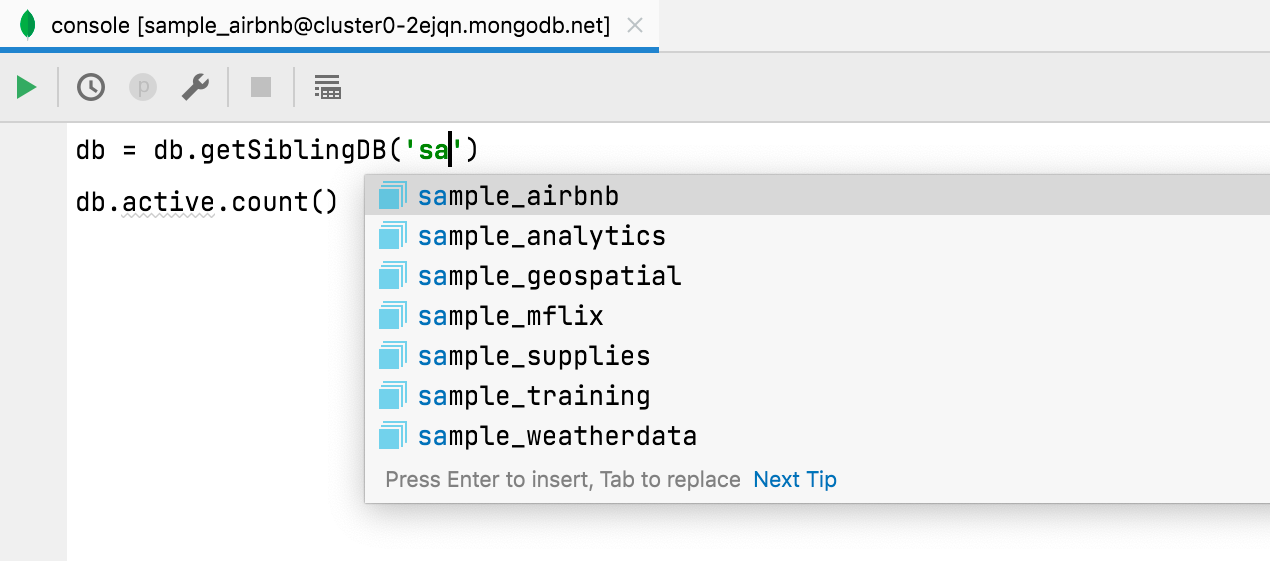
[MongoDB] Complétion de code pour les noms de bases de données
Les noms de base de données sont complétés lors de l'utilisation de getSiblingDB et les noms de collection sont complétés lors de l'utilisation de getCollection.
En outre, les noms de champ sont complétés et résolus s'ils sont utilisés à partir d'une collection qui a été définie via la complétion de code.
Importer/Exporter
Détection automatique de « First row is header »
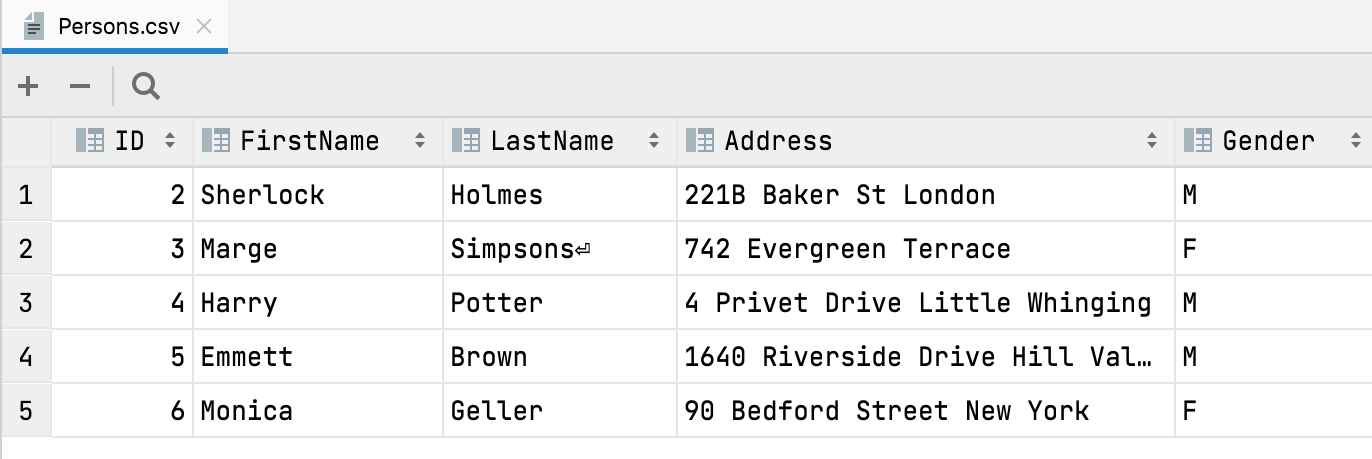
A partir de cette version, lorsque vous ouvrez ou importez un fichier CSV, DataGrip détecte automatiquement que la première ligne est l'en-tête et contient les noms des colonnes.
 Nouveautés et téléchargement de DataGrip 2021.3 EAP
Nouveautés et téléchargement de DataGrip 2021.3 EAP
Vous avez lu gratuitement 11 313 articles depuis plus d'un an.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.
Soutenez le club developpez.com en souscrivant un abonnement pour que nous puissions continuer à vous proposer des publications.